236 days or almost 8 months. I guess I kept my "More coming (probably not so) soon" promise.
But here we are again. I've utilised the past 7 months to hone my distraction skills and perfect procrastination. I am using the odd weekend home in Singapore to write up something I've shared with the biggest audience I've had the pleasure to speak for at DevFest 2024 Shanghai and a great bunch of Open Source enthusiasts at FOSSAsia 2025 in Thailand.
If your last 7 months were a bit more productive and you did me the honour to read (part) of the previous post, you might remember some impressions from Okinawa and the marine conservation activities I did there - paired with some pictures I took along the journey. That last part is exactly what this next post is about...
The attentive reader might've noticed I wrote verbose captions for every picture, even with some attempts at trying to be funny.

Not too much later, towards the end of the blogpost, things started turning to the rather... "lazy"? side.

Since I was in the middle of trying to understand the Gen AI hype, I decided to kick the tyres and build something that could help automate my laziness away... But before we start prompting, a bit of background on my Gen AI journey.
(don't care about the story, just want to know about how you can help out? I GOT YOU COVERED: click here to skip to the next section)
Full table of contents:
The background story
It’s September 2023, and I’ve just joined DoiT. The generative AI space was in full hype mode since the launch of ChatGPT in November 2022. Not long after, Google launched Bard, and Meta released (and later leaked "open-sourced") — their powerful LLaMA models in February. Microsoft added Copilot to Microsoft 365, Anthropic introduced Claude in March, and Amazon launched Bedrock as part of AWS. It was a busy time — and to be honest, I mostly kept my head in the sand, hoping the hype storm would blow over.
My exposure so far was mainly limited to one of my good (photography) friends who had taken this awesome picture:

but then decided to turn it into this:


No wonder that, when I was trying to answer the question "where is (Gen) AI going?" for my first presentation on Gen AI, the "bad" of my "the good, the bad and the ugly" was the biggest portion.
It looked something like this:
The bad 😬

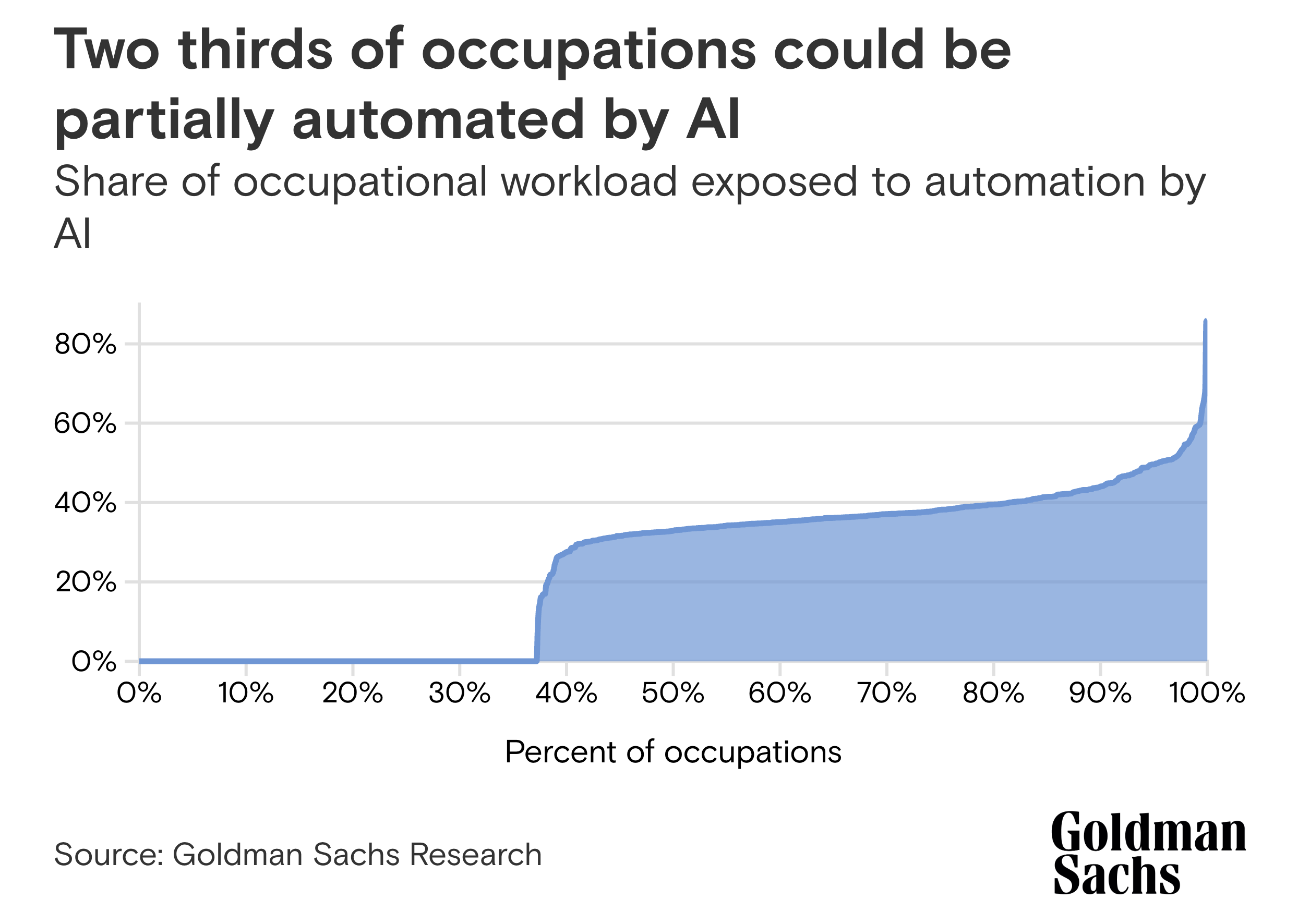
- Job loss: According to a report by Goldman Sachs, 2 out of 3 jobs in the US would be exposed to some degree of automation by AI.
- Uproar in the creative industries: AI winning art competitions, intellectual property lawsuits left, right and centre, and strikes in Hollywood.



- Misinformation and disinformation: With tailored content creation becoming available for pocket change, combined with hallucinating LLMs, false information (purposefully) became more widespread.

- Existential threat: A topic that has always been present in movies (thinking of The Matrix), some leading figures in the industry sounded the alarm bell... while others claim we won't run blindly into our own doom. Some counterweights have popped up as well such as Google DeepMind forming a new org specifically focusing on AI safety and Ilya Sutskever founding a new company focusing on "safe superintelligence".


If you made it this far without the sudden onset of a depression - good job! I'll try to brighten up from here.
The good 🎉
Onwards from the doom and gloom section, there are also lots of things to be excited about:
- Economic tailwinds: According to leading banks and consulting firms, Generative AI could boost global GDP by up to 7%, or $7 trillion. This growth has the potential to raise incomes, improve standards of living, increase government spending on public services, and create new opportunities in financial markets.

- Higher productivity: Somewhat related, McKinsey found that AI is bound to automate up to 60 or 70% of our work, allowing us to get more things done in the same amount of time and allocating that time to higher-level decision making and higher-value work.

- Democratising knowledge: Who hasn't used one of the friendly bots to learn about a new topic? Gen AI puts knowledge at our fingertips with a barrier even lower than before. The World Economic Forum has written a piece about how Gen AI could be society's new equalizer, providing more equal opportunity to everyone.

- Business opportunities: Gen AI also lowers the barrier for existing or new companies to build products that are AI-enabled. For this, I can recommend the "Opportunities in AI" talk by Andrew Ng in which he gives an overview of the landscape and discusses some of the drivers of these changes.
The ugly 🤡
Onto my personal favourite section. The failures. To compensate for all the doom and gloom, I probably spent a disproportionate amount of time laughing at people's creations on the internet. From:
Will Smith eating spaghetti:
Will Smith eating spaghetti
byu/chaindrop inStableDiffusion
to memes coming to life:
Dream Machine by Luma AI is just 3 days old.
— Madni Aghadi (@hey_madni) June 15, 2024
Now memes are becoming videos.
10 wild examples:
1. Distracted boyfriendpic.twitter.com/QXNDQdkY4P
to the pope (RIP) making headlines for wearing a puffer jacket:

to gluing cheese to pizza:
to one that struck close to home: a make it "MOAR BELGIAN 🇧🇪" series:
I asked ChatGPT to create a typical Belgian and make him increasingly Belgian with each photo
byu/Sergiow13 inbelgium
in which the final form was definitely missing some fries and beer.
These might all be a bit outdated by now, and I need to desperately update my research (and probably mental model of the world), but if this feels a bit confusing to you - that's exactly how I felt back then...
And by now, I know Sam Altman was right: "I don't know what happens next"... but at least I managed to generate some captions for my blogpost. Onto the techy stuff!

The inspiration
There were a few things that inspired me to go build something that would solve an "acute" problem, apart from all the noise in general about how good (or bad) LangChain and AI tooling was.
One was a blogpost by BAIR (Berkeley Artificial Intelligence Research) that talked about "The Shift from Models to Compound AI Systems". Up until that point, the LLM world felt like very much "researcher only" terrain to me, so I was happy to see how I could make my way "inside" the field from an engineering point-of-view. It discussed moving beyond large language models to integrating multiple specialised components — such as language models, retrieval systems, and external tools — into compound AI systems to offer enhanced performance, adaptability, and control.

Another inspiration (hey Andrew Ng is back!) came from the founder of Google Brain discussing the trend of AI Agents and their potential impact, covering topics like reflection, tool-use, planning, and multi-agent collaboration (maybe he knew about the A2A protocol coming up?!) on YouTube:
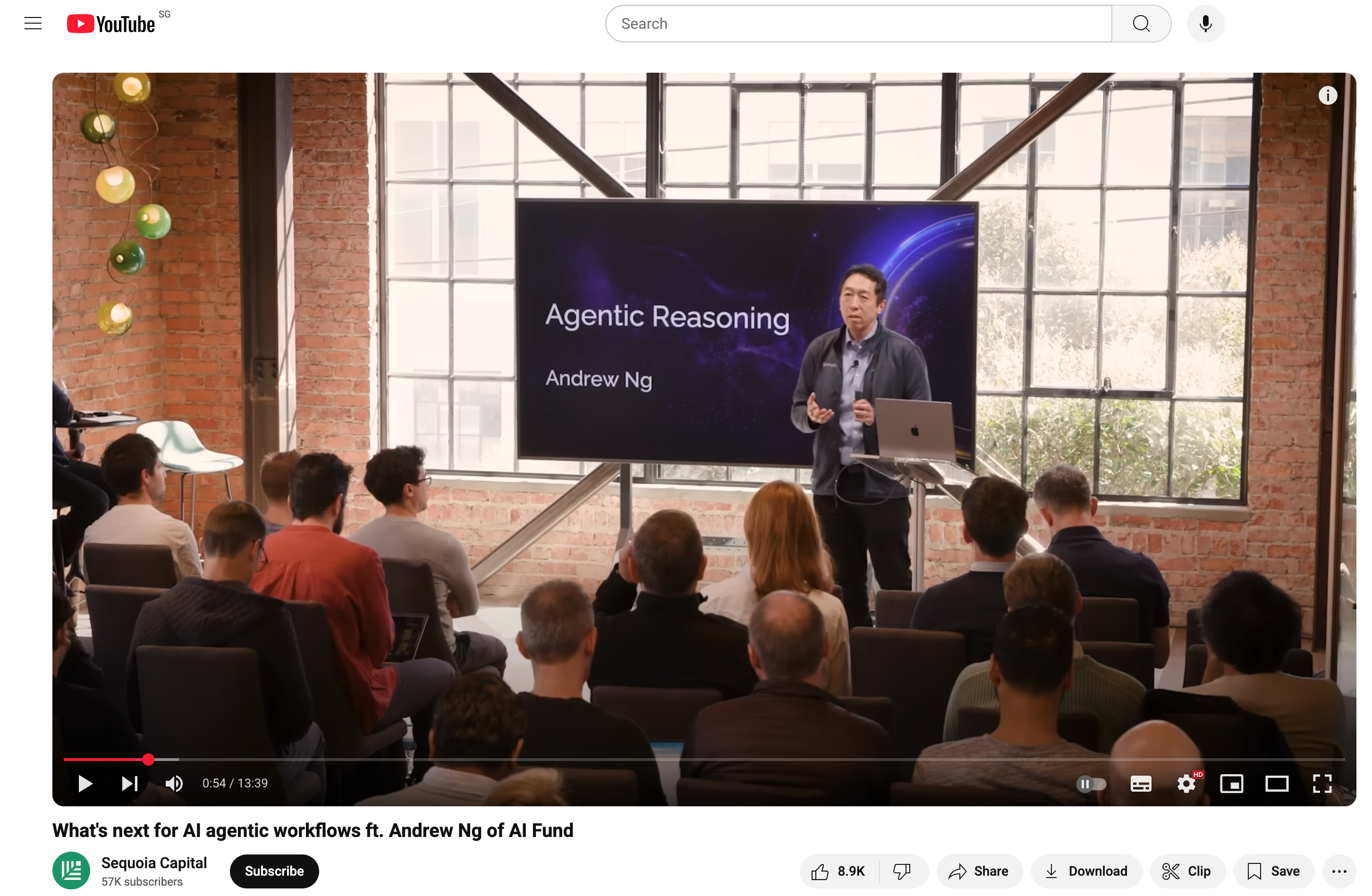
The demo
What better way to help you, the reader understand what I built than showing some caption generation in action? Initially I was planning to do a live demo for my talk in Shanghai, but last-minute logistical challenges (you won't believe it involved PowerPoint) prompted me to make a recording instead.
So below, a quick demo of the system I built to generate captions for my previous blogpost's pictures:
The demo shows the image captioning agent and how it combines LangChain for prompt and model orchestration, LangGraph for structuring the workflow as a stateful graph, and LangSmith for tracing and evaluation - covering my original intent after reading about compound AI systems.
Furthermore, it is powered by Google's multimodal model Gemini 1.5 Pro alongside Gemma 2 (Google's open-source LLM announced summer 2024) to generate captions.
Let's dig a bit deeper on all of this.
The tech
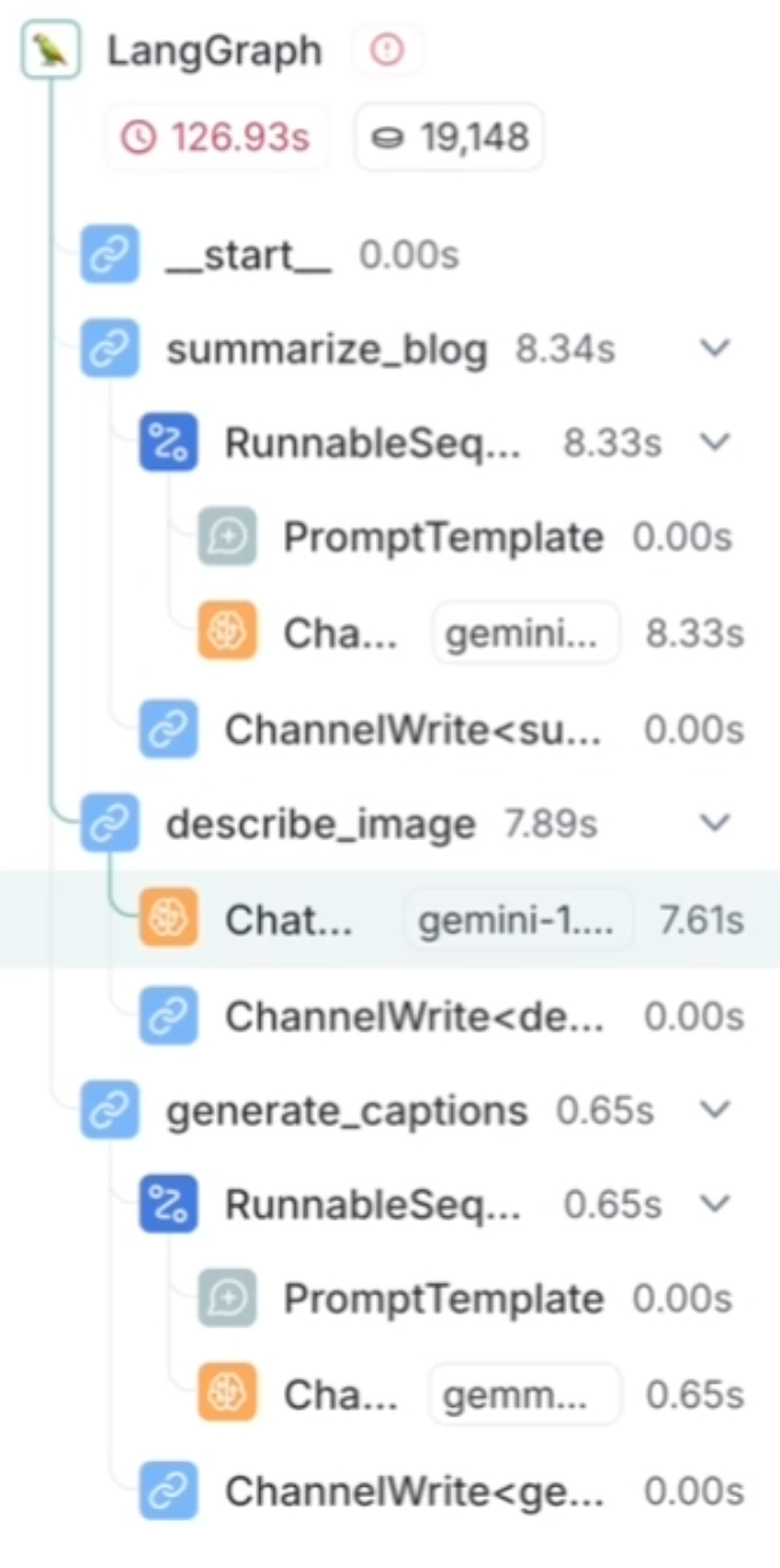
So what exactly did we see in the demo? Let's look at the different steps:
- Summarise blog: The script begins by summarising the blog content to extract key points with the help of Gemini 1.5 Pro. This summary provides context for generating captions.
- Describe image: We use Gemini 1.5 Pro to get a rich description of the photo.
- Generate captions: Given the blog as context and the description of the image, we ask Gemma 2 9B to come up with a few caption proposals.
- Human input: We pause the agent for human input, ensuring captions are not only contextually relevant but also user-approved.
- Depending on the input given by the human we:
- Refine captions: Ask Gemma to come up with new captions that adhere to the user's instructions.
- Save captions: We approve and save the caption.
LangGraph
This seems like the perfect time to introduce LangGraph. Some of you might have spotted it while watching the demo, but these steps perfectly fit a directed graph:
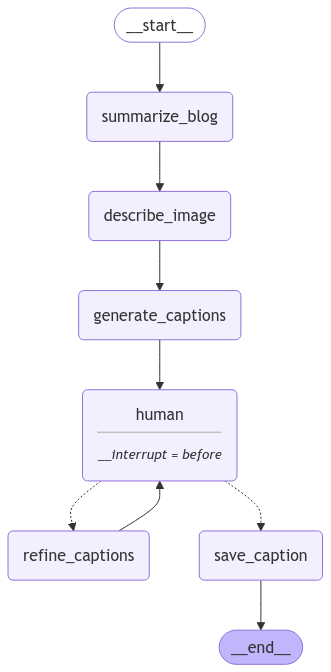
Without going too deep into graph theory, a graph consists of nodes and edges. The nodes control what happens and are basically tasks or functions while the edges control the flow of possible next steps. While LangChain was mostly supporting DAGs (Directed Acyclic Graphs), LangGraph introduces cycles and conditional branches, paramount to agentic behaviour (or, in our case, putting a human-in-the-loop).
While going through these different nodes, as you will see in the code, I updated the state (the StateGraph I used to construct the workflow is essentially a state machine). If this reminds you (even the | syntax) of another project dear to my heart, Apache Beam, I have good news: you're right; but I switched PTransforms for LLM-operations. LangGraph was apparently inspired by Apache Beam and Pregel.
Want to dive deeper into the concepts? Head to the LangGraph docs.
LangChain
Going one level deeper, into the nodes of my LangGraph graph, we meet its "older brother", LangChain.
While it does more than that, I use LangChain to format prompts, call LLMs, and parse outputs in a chain. I define a PromptTemplate which I feed into model calls after supplying some input parameters before feeding it to an output parser using the LangChain Expression Language (LCEL) pipeline syntax. LCEL allows you to “pipe” components together in a declarative way – for example, prompt | model | parser creates a sequence where the prompt’s output feeds into the model, and the model’s output feeds into a parser. Under the hood, LangChain treats each piece (prompt, LLM, parser) as a Runnable and the | operator composes them.
It allows you to quickly experiment with different models; e.g. I was using Gemini through Vertex AI on Google Cloud, but LangChain has many more integrations.
Another nifty feature in the LangChain box of magic are output parsers. These are useful, since:
- Not all models have this capability built-in (for example, Gemini 1.5 Pro does (it's called "Controlled Generation"), but Gemma does not).
- Your computer doesn't speak natural language, but might know how to deal with a JSON.
This is a powerful way to enforce structured output – the LLM is asked to produce an output conforming to the Pydantic schema, and the parser will validate/parse the LLM’s text into a Python object.
Gemini and Gemma
Let’s talk about the dynamic duo - at this point I have mentioned Gemini and Gemma a few times. While it feels a bit weird to write about Gemini 1.5 Pro and Gemma 2 while several Gemini 2.5 models have been announced and Gemma 3 is out, these were the models I built the demo with a few months back.
At the time of launch, Gemini 1.5 Pro stood out for the native multimodal design and its 1 million token context window (which was tested up to 10 million tokens). Back then (feels like ages ago), it was topping the leaderboards as well.
In one case, I had an image of me underwater holding a coral seedling – Gemini described everything from the colour of the water to the fact I was scuba diving and carrying coral fragments, noting the sense of scientific activity. Pretty cool, because it “knew” from the blog context that I passed it that this was a marine conservation activity, so it focused on that rather than, say, describing my hairstyle or my friend in the background. Context matters!
I have a CAPS LOCK todo item on my list to try out Gemini 2.5 Pro which is topping the LMArena leaderboard today and is promising to release a 2 million context window soon (I will need to write a lot more blogposts for that). As I might not need this much smarts for my use-case, Gemini 2.5 Flash would be good to try as well as it has a "thinking budget", which gives you control over the amount of tokens used during the reasoning phase.

Taking a closer look at the smaller, open-source brother, Gemma 2, which was released in the summer of 2024; it comes in 2B, 9B and 27B sizes, which is perfect if you want to test things locally with e.g. ollama.
That was my initial plan: keep everything local for quick iterations (which is why I love small, open-source models!) and keep some extra $£€ in my pocket - but the length of my blogpost prohibited this.
The first time I ran the code for an image, it gave me a range rather serious captions (“A tiny coral, a big impact: learning about reef restoration and contributing to Okinawa's underwater world”). Obviously, I wanted something shorter and funnier, so that's what I asked for in the human-in-the-loop step; generating "Planting coral seedlings is serious business, but I’m pretty sure Matthias is judging my dance moves underwater. 🐠😂". Guess another todo list item is to fine-tune Gemma to my jokes?...
Last month, Google also released Gemma 3, coming in 1B, 4B, 12B, and 27B parameter versions, making it fit for different hardware set-ups. It comes with multimodal capabilities, support for over 140 languages and a 128k-token window, probably making my usage of multiple models in my demo redundant.
If you want to dig deeper, I recommend checking out the technical reports linked below.


Groq
While Gemini handles the multimodal heavy lifting in my demo, Groq provides lightning-fast inference for open-source models, making it perfect for the iterative caption generation and refinement steps where speed matters more than cutting-edge multimodal capabilities.
The beauty of this architecture lies in its flexibility and highlights how different models (and hardware) might be the better choice under different circumstances. Need cutting-edge multimodal image description? Gemini is probably your best friend. Want to have interactive iteration in near real-time? Groq will shine for rapid text iteration during a human-in-the-loop refinement process. In practice, this meant I could get 5 caption proposals in seconds rather than waiting much longer for a premium model to process what is essentially a pure text generation task.
Moreover, LangChain's model abstraction made this mix-and-match approach seamless – the same prompt templates and parsing logic work regardless of whether I'm calling Gemini or Groq, I just needed to handle the structured output differences (Gemini's native structured output vs Groq with Pydantic output parsers).
How did Groq achieve this lightning-fast inference? They developed a proprietary processor called a Language Processing Unit (LPU), designed from the ground up for AI inference. Their approach is based on 4 key design principles, as outlined in their whitepaper:
- Software-first: LPUs employ a programmable assembly line architecture, which enables the AI inference technology to use a generic, model-independent compiler, while, to maximize hardware utilization on GPUs, every new AI model requires coding of model-specific kernels.
- Programmable Assembly Line Architecture: while GPUs operate in a multi-core “hub and spoke” model, which involves more overhead to shuttle data back and forth between the compute and memory units, the LPU features data "conveyor belts" which move instructions and data between the chip's SIMD function units, eliminating bottlenecks within and across chips.
- Deterministic Compute & Networking: Every execution step is completely predictable, required to make an assembly line run efficiently. Data flow is statically scheduled by the software during compilation, and executes the same way every time the program runs.
- On-chip memory: LPUs include both memory and compute on-chip, vastly improving the speed of storing and retrieving data while eliminating timing variation. Groq's on-chip SRAM has memory bandwidth upwards of 80 terabytes/second, while GPU off-chip HBM clocks in at about eight terabytes/second.
Groq supports inference for Gemma 2 9B and a bunch of other open source models at modest prices: groq.com/pricing
LangSmith
LangSmith is LangChain's observability and evaluation platform. It's a very helpful tool to peek under the hood of your LLM application, visualising the flow of a request through the different steps, and giving you insight into the input and output of each node in the graph.
The setup was surprisingly easy – just add some environment variables and it automatically started tracing every step of my workflow. Beyond just visualising the separate steps, it also showed the latency for each of them, helping me understand where Groq was shining compared to Gemini.
On the evaluation side, LangSmith offers tooling to build datasets that can help evaluate your agents for correctness, relevance, and other quality metrics. This makes it a powerful toolkit for iteratively improving your prompts or deciding when to swap your small open-source model for a more powerful alternative. As a nice bonus, it's compatible with OpenTelemetry standards – an open-source observability project that's dear to my heart.
In a nutshell, LangSmith provides the necessary tooling to move beyond your weekend idea into a full-fledged production project.
The result
So, how did I end up using what I learned and coded up? I used it to write and inspire some of the updated captions here!
The full code I used can be found in the LangWhatNot repo on my GitHub - go take a look and let me know what you think :)
Too lazy to check it out yourself? I did a run-through with an example I used:
I also included a full log of the run here and the final output here.
The future (mine and... yours?)
Looks like we're off to a fun start: I learned a few things while building something that makes my life a bit easier - but while writing this blogpost my todo list only got longer. Here's what I'm excited to explore next:
Model Improvements
- I already mentioned testing out the new Gemini 2.5 models for their improved capabilities
- I've been itching to get my hands dirty with fine-tuning one of the open source models (looking at you, Gemma 3 👀) to better match my style out of the box.
User Interfaces & Experience
- I'd like to give my Agent a proper face rather than just CLI interaction - some experimentation with Gradio or Streamlit would make it more accessible (maybe I can even let you interact with it!)
Emerging Standards & Protocols
- Model Context Protocol (MCP) got a lot of attention lately and with Google, OpenAI, and Amazon showing support, it's poised to become the industry standard. I've written a small blogpost about our own MCP server at DoiT and can't wait to try build with it myself.
- At Google Cloud Next 2025, Google released the Agent2Agent Protocol (A2A) and Agent Development Kit - I will need to fit them into my mental model of the broader ecosystem.
Looking back at this journey – from somewhat of a Gen AI skeptic to someone who built something somewhat useful using it – I am hopeful on how Gen AI as a tool can be useful when you focus on solving real problems rather than chasing the hype. It feels good to take the chance to explore the landscape of sprawling tooling out there while building something that's actually personally useful. And you get thrown in the dopamine hit for free :)
What's for sure is that, for better or worse, we're stuck with LLMs and GenAI for the foreseeable future, and we better get used to integrating them into our workflows and think of them as an extension of our existing toolchain. The key? Start small, solve your own problems first, and don't be afraid to get your hands dirty with the code. You might just surprise yourself with what you can build.