236 days or almost 8 months. I guess I kept my "More coming (probably not so) soon" promise.
But here we are again. I've utilised the past 7 months to hone my distraction skills and perfect procrastination. I'm using an odd weekend at home in Singapore to write-up something I've shared with the biggest audience I've had the pleasure to speak for at DevFest 2024 Shanghai and a great bunch of Open Source people at FOSSAsia 2025 in Thailand.
If your last 7 months were a bit more productive and you did me the honour to read (part) of the previous post, you might remember some impressions from Okinawa and the marine conservation activities I did there - paired with some pictures I took along the journey. That last part is exactly what this next post is about...
The attentive reader might've noticed I started with writing verbose captions for every picture, even with some attempts at trying to be funny.

Not too much later, towards the end of the blogpost, things started turning to the rather... "lazy"? side.

Since I was in the middle of trying to understand the Gen AI hype, I decided to kick the tyres and build something that could help automate my laziness away...
The inspiration
There were a few things that inspired me to go build something that would solve an "acute" problem, apart from all the noise in general about how good (or bad) LangChain and AI tooling was.
One was a blogpost by BAIR (Berkeley Artificial Intelligence Research) that talked about "The Shift from Models to Compound AI Systems". Up until that point, the LLM world felt like very much "researcher only" terrain to me, so I was happy to see how I could make my way "inside" the field from an engineering point-of-view. It discussed moving beyond large language models to integrating multiple specialised components — such as language models, retrieval systems, and external tools — into compound AI systems to offer enhanced performance, adaptability, and control.

Another inspiration (hey Andrew Ng is back!) came from the founder of Google Brain discussing the trend of AI Agents and their potential impact, covering topics like reflection, tool-use, planning, and multi-agent collaboration (maybe he knew about the A2A protocol coming up?!) on YouTube:
The demo
What better way to help to understand the reader what I built than showing some caption generation in action? Initially I was planning to do a live demo for my talk in Shanghai, but last minute logistical challenges (you won't believe it involved PowerPoint) prompted me to make a recording instead.
So below, a quick demo of the system I built to generate captions for my previous blogpost's pictures:
The demo shows the image captioning agent and how it combines LangChain for prompt and model orchestration, LangGraph for structuring the workflow as a stateful graph, and LangSmith for tracing and evaluation - covering my original intent of finding out a bit more about the LangChain ecosystem.
Furthermore, it is powered by Google's multimodal model Gemini 1.5 Pro alongside Gemma 2 (Google's open-source LLM announced in summer 2024) to generate captions.
Let's dig a bit deeper on all of this.
The tech
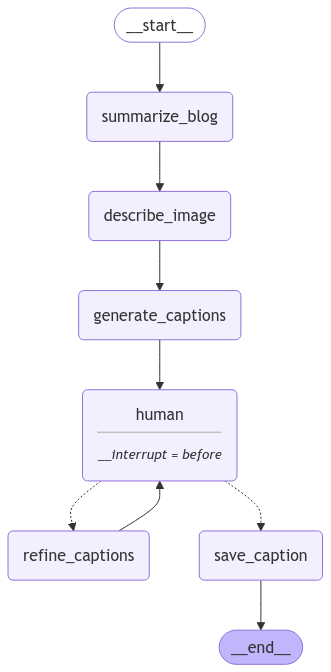
So what exactly did we see in the demo? Let's look at the different steps:
- Summarise blog: The script begins by summarising the blog content to extract key points with the help of Gemini 1.5 Pro. This summary provides context for generating captions.
- Describe image: We use Gemini 1.5 Pro to get a rich description of the photo.
- Generate captions: Given the blog as context and the description of the image, we ask Gemma 2 9B to come up with a few caption proposals.
- Human input: We pause the agent for human input, ensuring captions are not only contextually relevant but also user-approved.
- Depending on the input given by the human we:
- Refine captions: Ask Gemma to come up with new captions that adhere to the user's instructions.
- Save captions: We approve and save the caption.
LangGraph
This seems like the perfect time to introduce LangGraph. Some of you might have spotted it while watching the demo, but these steps perfectly fit a directed graph:
Without going too deep into graph theory, a graph consists of nodes and edges:
- The nodes control what happens and are basically tasks or functions
- The edges control the flow of possible next steps.
While LangChain was mostly supporting DAGs (Directed Acyclic Graphs), LangGraph introduces cycles and conditional branches, paramount to agentic behaviour (or, in our case, putting a human-in-the-loop).
Running through these different nodes, as you will see in the code, the state gets updated (the StateGraph I used to construct the workflow is essentially a state machine). If this reminds you (even the | syntax) of another project dear to my heart, Apache Beam, I have good news: you're right; but the PTransforms got switched for LLM-operations. LangGraph was apparently inspired by Apache Beam and Pregel.
Want to dive deeper in the concepts? Head to the LangGraph docs.
LangChain
Going one level deeper, into the nodes of my LangGraph graph, we meet its older brother, LangChain.
While it's more capable than that, in the demo LangChain gets used to format prompts, abstract LLM calls, and parse outputs in a chain.
For prompt formatting, I define a PromptTemplate which I feed into model calls after supplying some input parameters before feeding it to an output parser using the LangChain Expression Language (LCEL) pipeline syntax.
LCEL allows you to construct chains: “piping” components together in a declarative way – for example, prompt | model | parser creates a sequence where the prompt’s output feeds into the model, and the model’s output feeds into a parser. Under the hood, LangChain treats each piece (prompt, LLM, parser) as a Runnable and the | operator composes them.
LLM abstraction It allows you to quickly experiment with different models; e.g. I was using Gemini through Vertex AI on Google Cloud, but LangChain has many more integrations.
Another nifty feature in the LangChain box of magic are output parsers. These are useful, since:
- Not all models have this capability built-in (for example, Gemini 1.5 Pro does (it's called "Controlled Generation"), but Gemma does not).
- Your computer doesn't speak natural language, but might know how to deal with a JSON.
This is a powerful way to enforce structured output – the LLM is asked to produce an output conforming to the Pydantic schema, and the parser will validate/parse the LLM’s text into a Python object.
Gemini and Gemma
Let’s talk about the dynamic duo - at this point I have mentioned Gemini and Gemma a few times. While it feels a bit weird to write about Gemini 1.5 Pro and Gemma 2 while several Gemini 2.5 models have been released and Gemma 3 is out, these were the models I built the demo with a few months back.
At the time of launch, Gemini 1.5 Pro stood out for its native multimodal design and its 1 million token context window (which was tested in research up to 10 million tokens). Back then (feels like ages ago), it was topping the leaderboards as well.
In one case, I had an image of me underwater holding a coral seedling – Gemini described everything from the colour of the water to the fact I was scuba diving and carrying coral fragments, noting the sense of scientific activity. Pretty cool, because it “knew” from the blog context that this was a marine conservation activity, so it focused on that rather than, say, describing my hairstyle or my friend in the background. Context matters!
I have a CAPS LOCK todo item on my list to try out Gemini 2.5 Pro which is topping the LMArena leaderboard today and is promising to release a 2 million context window soon (I will need to write a lot more blogposts for that). As I might not need this much smarts for my use-case, Gemini 2.5 Flash would be good to try as well as it has a "thinking budget", which gives you control over the amount of tokens used during the reasoning phase. This means you can balance between speed and depth of thought - using more tokens when you need careful analysis and fewer when you need quick responses, all while keeping costs predictable.

Taking a closer look at the smaller, open-source brother, Gemma 2, which was released in the summer of 2024; it comes in 2B, 9B and 27B sizes, which is perfect if you want to test things locally with e.g. ollama.
That was my initial plan: keep everything local for quick iterations (which is why I love small, open-source models!) and keep some extra $£€ in my pocket - but the length of my blogpost prohibited this.
The first time it ran for an image, it gave me a range rather serious captions (“A tiny coral, a big impact: learning about reef restoration and contributing to Okinawa's underwater world”). Obviously, I wanted something shorter and funnier, so that's what I asked for in the human-in-the-loop step; generating "Planting coral seedlings is serious business, but I’m pretty sure Matthias is judging my dance moves underwater. 🐠😂". Guess another todo list item is to fine-tune Gemma to my jokes?...
Last month, Google also released Gemma 3, coming in 1B, 4B, 12B, and 27B parameter versions, making it fit for different hardware set-ups. It comes with multimodal capabilities, support for over 140 languages and a 128k-token window, probably making my usage of multiple models in my demo redundant.
If you want to dig deeper, I recommend checking out the technical reports linked below.


The future (mine and... yours?)
Looks like we're off to a fun start: I learned a few things while building something that makes my life a bit easier - but while writing this blogpost my todo list only got longer. Here's what I'm excited to explore next:
Model Improvements
- I already mentioned testing out the new Gemini 2.5 models for their improved capabilities
- I've been itching to get my hands dirty with fine-tuning one of the open source models (looking at you, Gemma 3 👀) to better match my style out of the box.
User Interfaces & Experience
- I'd like to give my Agent a proper face rather than just CLI interaction - some experimentation with Gradio or Streamlit would make it more accessible (maybe I can even let you interact with it!)
Emerging Standards & Protocols
- Model Context Protocol (MPC) got a lot of attention lately and with Google, OpenAI, and Amazon showing support, it's poised to become the industry standard. I am curious to explore what it can do next.
- At Google Cloud Next 2025, Google released the Agent2Agent Protocol (A2A) and Agent Development Kit - I will need to fit them into my mental model of the broader ecosystem.