Approximately 3 seconds. That's how long it took our AI assistant to assess the ticket drafted by our customers. Not bad, but closer to "should I get a coffee in the meantime" than I wanted it to be and not exactly the snappy, interactive experience we had in mind when we built CaseIQ during our company hackathon last year.
(don't care about the backstory and just want the numbers? I GOT YOU COVERED: click here to skip to the experiment)
You might be wondering what CaseIQ even is... During my time at DoiT I've had the humbling privilege to assist some of the biggest and most innovative companies (think Hackerrank, Pinecone, ...) in the cloud. Alongside our FinOps offering and as part of our uncapped access to senior cloud expertise, customers can interact with us in several ways and on several topics, ranging from brainstorming and POC'ing new initiatives (my favourite!), help customers leverage our FinOps platform to cut costs, or (the most stressful one) assist them when their services are down.
As part of our strive for innovation, we have a yearly hackathon in which our team participated last year, and this is where CaseIQ was born. CaseIQ is an intelligent case management augmentation system that extracts key facts and helps guide the customer to provide our engineers with as much relevant information as possible while they are drafting the explanation of their problem - think for example database version, error message, or query plan. It complements Ava, responsible for AI driven customer query resolution, and activating CaseIQ when it’s detected that human intervention is needed, in line with our “powered by technology, perfected by people” vision.
In the initial hackathon, we used the OpenAI company subscription to create an MVP, which rolled out at the end of 2024 and hit a second version a few months after.
Having enjoyed launch success, we came up with a roadmap of improvements for 2025, one of which was to reduce the latency on the system, providing customers with quicker feedback and opening up new instant messaging channels, to bring our services closer to where our customers already are.
Full table of contents:
- TLDR;
- The Context
- The Experiment
- The Evaluation
- The Results
- Architectural considerations
- Anecdotal evidence from manual review
- The conclusion
TLDR;
In this article, I'll walk through how we reduced inference latency in a production AI customer support system while maintaining acceptable performance quality. Through a comprehensive 2-week experiment comparing OpenAI's GPT-4o baseline against GPT-4.1 mini and three Groq-hosted Llama models across 21,517 traces and 755 tickets, we managed to squeeze out:
- 4-5x latency improvements with Llama 3.1 8B across most tasks (e.g., severity inference: 605ms → 126ms)
- 2-3x speed gains with Llama 3.3 70B while maintaining >90% agreement rates with GPT-4o baseline
- Up to 50x cost reductions with open-source models hosted on Groq's specialised hardware
- Manual review scores showing acceptable quality trade-offs: GPT-4o (0.92-0.96) vs. Llama 3.1 8B (0.55-0.88) vs. Llama 3.3 70B (0.88-0.96)
And ended up recommending a hybrid approach using different models optimised for each task, combined with architectural changes to return results independently, reducing the total inference time from ~3 seconds to under 1 second, achieving a ~4x overall speedup while reducing operational costs by orders of magnitude.
The Context
CaseIQ extracts key facts from customers' descriptions of problems they have in their cloud infrastructure. The system performs five inference tasks:
- Platform Inference: Detecting which cloud service provider (AWS, GCP, Azure, ...)
- Product Inference: Identifying the specific cloud service involved
- Severity Inference: Assessing ticket priority
- Asset ID Inference: Extracting specific project/account/resource identifiers
- Technical Details Inference: Determining if the ticket includes additional technical information that our engineers need
The challenge: our GPT-4o-based system was taking 3+ seconds for inference, preventing the system from feeling as snappy as we had envisioned and making real-time integration with support channels (like Slack) impractical. We needed near-instantaneous responses to enable truly interactive customer experiences.
The Experiment
The different models (and why Groq caught my eye)
We compared our GPT-4o baseline against four alternatives:
- GPT-4.1 mini (OpenAI): Newer, faster model from OpenAI
- Llama 3.1 8B (Meta on Groq): Small model on specialised LPU hardware for maximum speed
- Llama 3.3 70B (Meta on Groq): Larger model balancing capability with speed
- Llama 4 Scout 17B (Meta on Groq): Preview model with promising performance
Groq's Language Processing Units (LPUs) are specialised hardware designed specifically for LLM inference, promising exceptional speed and ultra-low latency compared to traditional GPU-based inference.
The Implementation
Since we were already using LangChain, adding the comparison models was straightforward: we added ChatGroq calls alongside our existing ChatOpenAI integration. We made these calls asynchronously to avoid impacting the critical path of our application.
We leveraged LangSmith for comprehensive instrumentation, which provided:
- Latency measurements for each model/task combination
- Token usage (and cost tracking for OpenAI)
- Input/output logging for quality analysis
- Error rates and success metrics
- Metadata attachment (e.g., final ticket IDs for downstream analysis)
Over 2 weeks, we collected 21,517 total traces and 755 unique customer cases.
The Evaluation
While not entirely accurate, we opted to use GPT-4o as an easy baseline to produce an automated evaluation metric for our system to see how close the other models would match its predictions. We calculated the following metrics:
- Agreement rate: Percentage of outputs matching GPT-4o baseline
- Success rate: Percentage of successful API calls (non-failures)
- Latency speedup: Improvement factor compared to GPT-4o baseline
- Cost per 1000 requests: Average cost per 1000 requests in USD
- Cost ratio: Cost improvement factor compared to GPT-4o baseline
Aware of the shortcomings of the automated metrics, we conducted human evaluation on a sample using task-specific scoring criteria:
- Platform/Product: Exact match required (score: 0 or 1)
- Severity: Exact match = 1, one "severity" off = 0.5, else 0
- Asset ID: Exact match = 1, else 0
- Technical Details: Proportional scoring based on correctly identified details (subtract 1/M for each missing detail, where M = total expected details)
Not all tasks are created equal though; e.g. while platform, product and asset ID are usually more clearcut and a binary 'true/false' evaluation makes sense, there are more considerations for severity and technical details in our particular use case:
- Especially for Low vs Normal in the severity task, there is usually room for debate. Since, even among engineers, there is sometimes debate around this, a more "relaxed" evaluation than perfect match makes sense.
- Since we don't show the inferred technical details to the customer (rather, just a checkbox if we found the details in their issue description), we also don't require an exact match, rather just a "sensical" answer.
We included these 2 types of visualisations: Violin Plots: Show full latency distribution with kernel density estimation. Width indicates frequency of latency values; white dot = median; thick black bar = interquartile range. We removed outliers using IQR filtering (Q1 - 1.5×IQR, Q3 + 1.5×IQR). Histogram/KDE Plots: Frequency distribution with smooth KDE overlay. We capped latency at 2000ms and removed 5% most extreme measurements from each tail for cleaner visualisation.
The Results
In this section, we'll be sharing the results of our experiment, along with the visualisations discussed above and our thoughts on those numbers.
Manual review results
The following table shows manual review scores across all models and tasks, where higher scores indicate better performance:
| Model | Platform | Product | Severity | Asset ID | Technical Details |
|---|---|---|---|---|---|
| gpt-4o | 0.92 | 0.92 | 0.84 | 0.95 | 0.96 |
| gpt-4.1-mini-2025-04-14 | 0.92 | 0.88 | 0.76 | 0.95 | 0.78 |
| llama-3.1-8b-instant | 0.88 | 0.83 | 0.72 | 0.55 | 0.84 |
| llama-3.3-70b-versatile | 0.95 | 0.88 | 0.72 | 0.95 | 0.96 |
| llama-4-scout-17b | 0.93 | 0.86 | 0.74 | 1.00 | 0.87 |
We discuss these numbers below on a task-per-task basis.
Automated baseline comparison
Platform Inference
| Model | Agreement Rate | Success Rate | Median Latency | Speedup vs GPT-4o | Cost per 1K ($) | Cost Ratio |
|---|---|---|---|---|---|---|
| gpt-4o | - | 99.99% | 571.0ms | 1.0x | 1.28 | 1.0x |
| gpt-4.1-mini | 87.8% | 99.92% | 502.0ms | 1.14x | 0.20 | 6.25x |
| llama-3.1-8b | 71.7% | 98.13% | 141.0ms | 4.05x | 0.03 | 37.65x |
| llama-3.3-70b | 92.1% | 84.72% | 249.0ms | 2.29x | 0.46 | 2.78x |
| llama-4-scout-17b | 91.2% | 42.95% | 310.0ms | 1.84x | 0.16 | 8.00x |
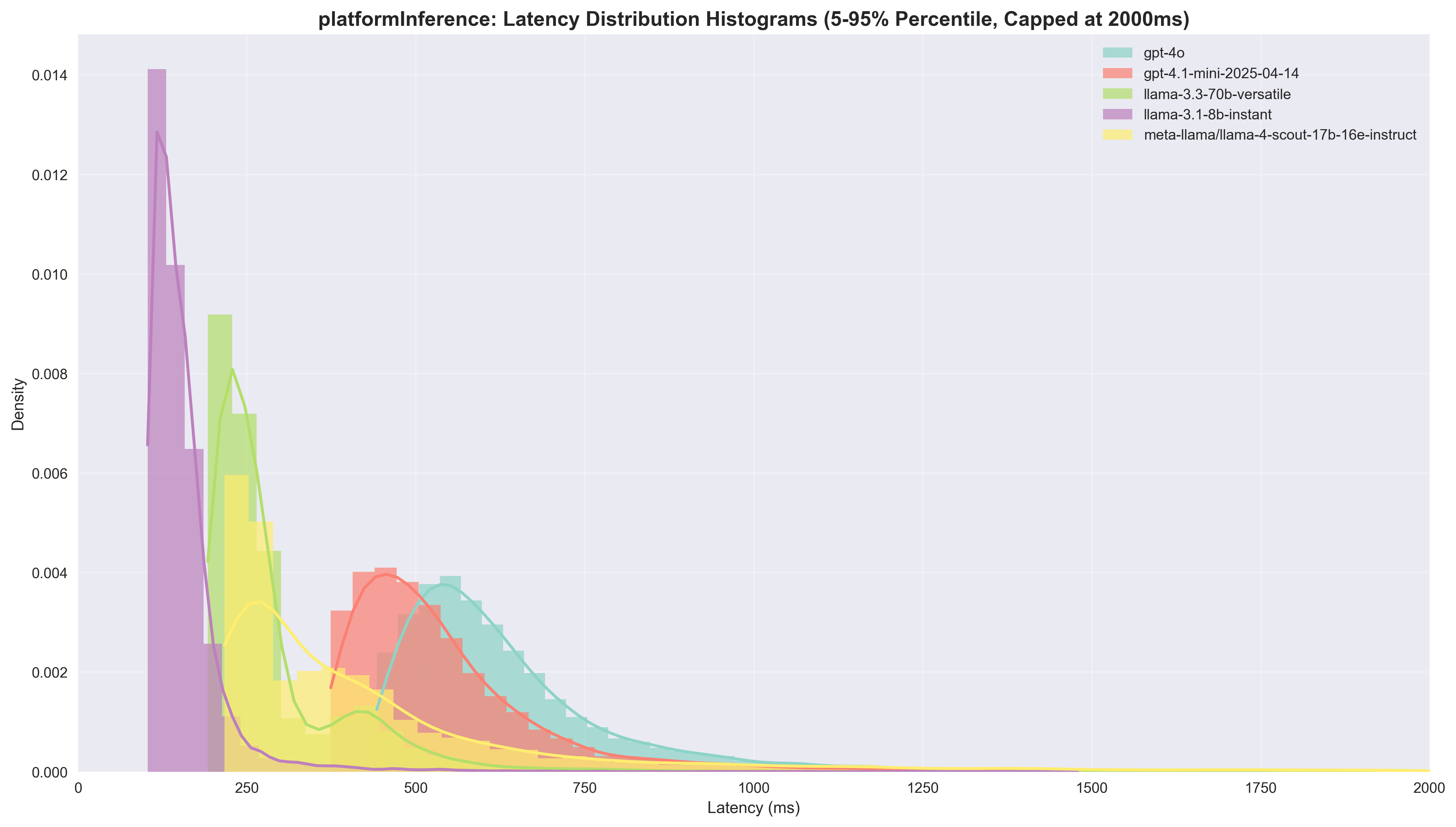
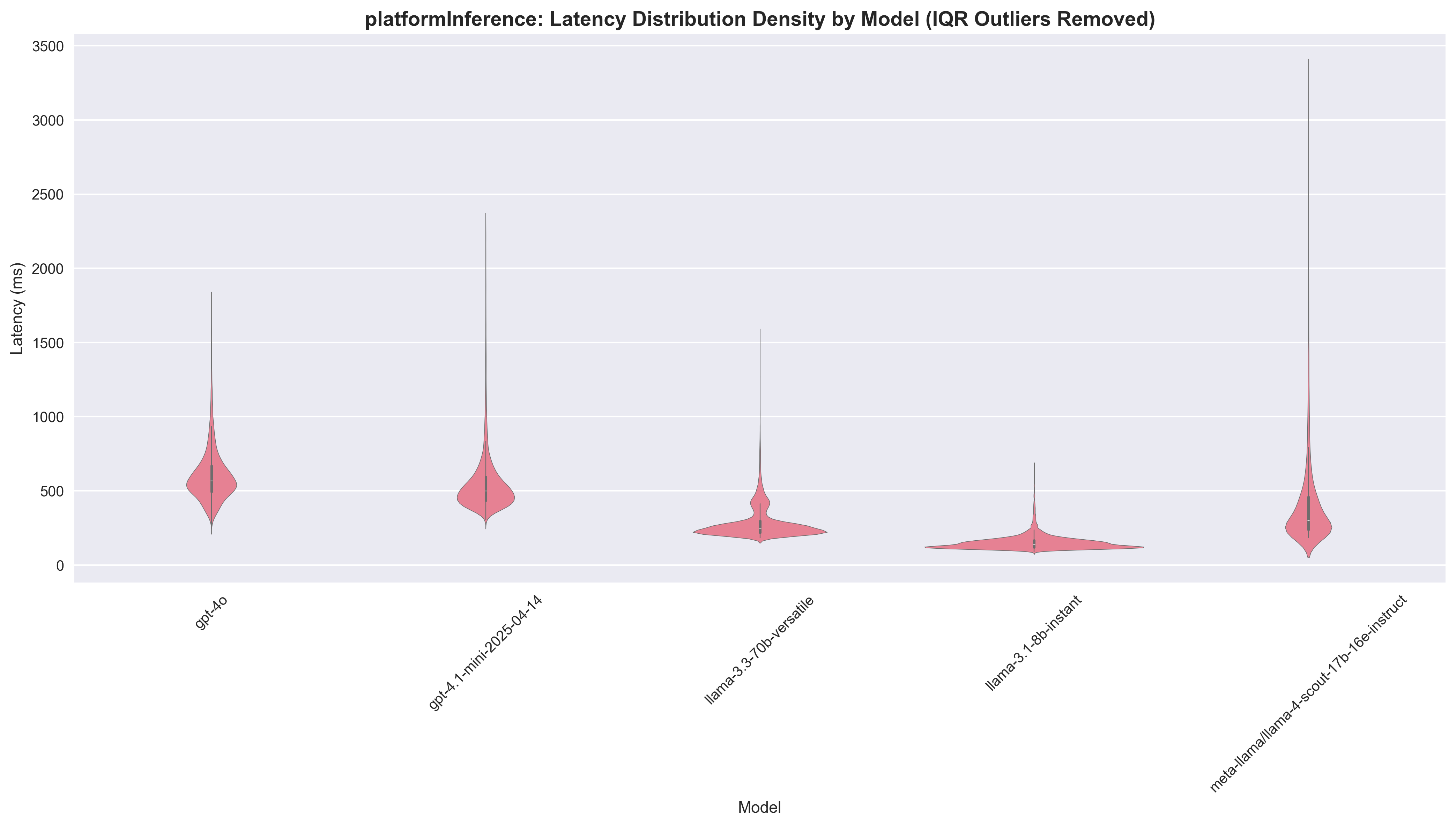
Key Insights:
- Llama 4 Scout has an unacceptably low success rate (42.95%), making it unusable in production
- Llama 3.1 8B delivers exceptional speed (4.05x) and cost savings (37.65x) with reasonable agreement (71.7%)
- Llama 3.3 70B achieves the highest agreement rate (92.1%) with solid speed improvements (2.29x)
- GPT-4.1 mini offers mostly cost reduction (over 6x) and decent agreement rate, but minimal speedup
Manual Review: Looking at the manually obtained data (much smaller sample, but human labels), we see Llama 3.1 8B holding its own at a 0.88 score, not lagging far behind the other models. Llama 3.3 70B takes the performance crown again.
Recommendation: while the main aim of the project was speed gain and increased interactivity, the platform inference task is too crucial to justify the good performance of Llama 3.1 8B at this point. We think it’s prudent to keep the Llama 3.3 70B in this spot for now and live with the 108ms performance hit, but will see if further prompt improvements might open up the road to 3.1 8B.
Product Inference
| Model | Agreement Rate | Success Rate | Median Latency | Speedup vs GPT-4o | Cost per 1K ($) | Cost Ratio |
|---|---|---|---|---|---|---|
| gpt-4o | - | 99.98% | 851.0ms | 1.0x | 14.84 | 1.0x |
| gpt-4.1-mini | 83.2% | 99.96% | 691.0ms | 1.23x | 2.37 | 6.26x |
| llama-3.1-8b | 69.1% | 90.61% | 406.0ms | 2.10x | 0.32 | 46.38x |
| llama-3.3-70b | 80.5% | 98.37% | 761.0ms | 1.12x | 3.75 | 3.96x |
| llama-4-scout-17b | 78.8% | 95.65% | 508.0ms | 1.68x | 0.75 | 19.79x |
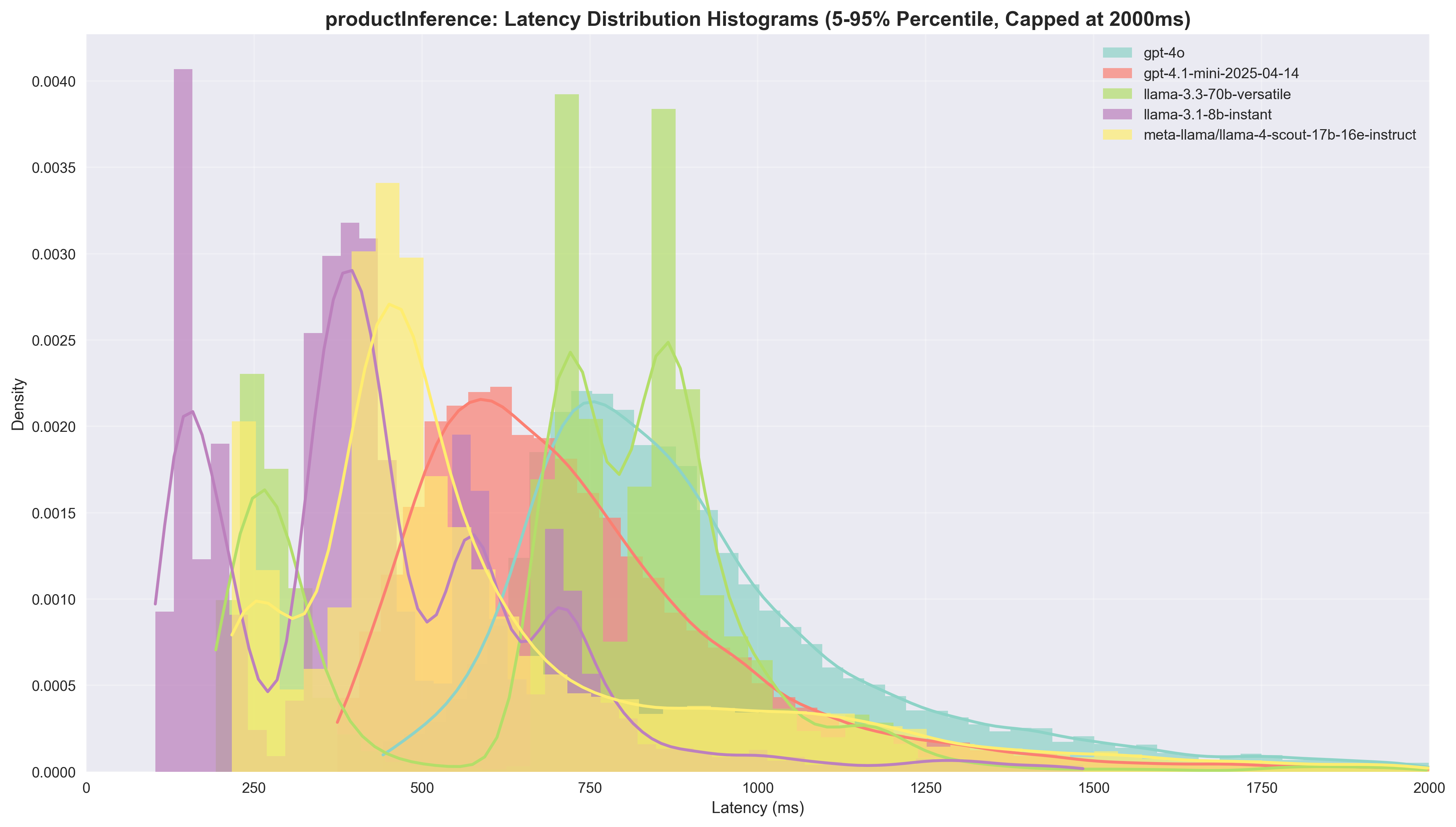
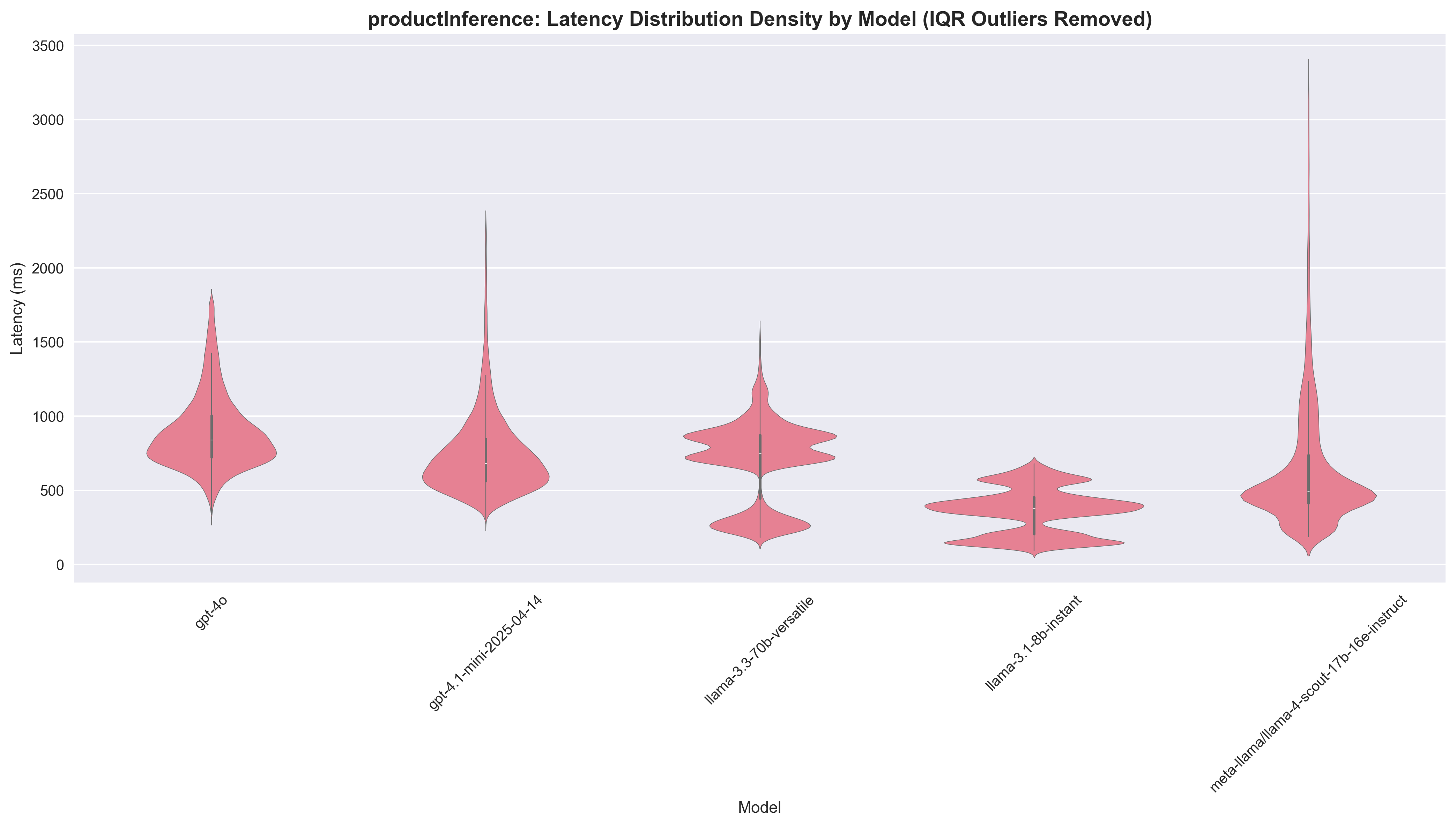
Key Insights:
- Llama 3.1 8B delivers the best speed performance at 2.10x speedup with the fastest absolute latency (406ms), though at the cost of lower agreement rate (69.1%) and success rate (90.61%)
- Llama 4 Scout provides a solid 1.68x speedup with reasonable agreement (78.8%) and excellent cost savings (19.79x)
- GPT-4.1 mini offers minimal speed improvement (1.23x) but maintains high agreement rate (83.2%) and success rate (99.96%)
- Llama 3.3 70B provides only modest speed gains (1.12x), but comes in second on the agreement rate
In the visualisations, we see an interesting pattern here: the Groq models have a few more "bumps" compared to the OpenAI models. Our understanding is that this is because:
- Product inference has a dynamic prompt that can change in length based on the platform that was inferred
- Groq inference is more sensitive to prompt length compared to the OpenAI inference methods, affecting the time-to-first-token (TTFT)
Manual Review: Product inference shows more variation in performance, with Llama 3.1 8B scoring 0.83 compared to GPT-4o's 0.92. The other models hover in between.
Recommendation: Llama 4 Scout makes a compelling case here, balancing nicely between speed, performance and cost savings. However, since this model is still in preview, it might be cautious to stick with Llama 3.1 8B, gaining some speed and cost savings over performance. Moreover, since product inference sits in the critical path of technical detail inference (we need to know platform and product before we can infer technical details), speedup is even more important here.
Severity Inference
| Model | Agreement Rate | Success Rate | Median Latency | Speedup vs GPT-4o | Cost per 1K ($) | Cost Ratio |
|---|---|---|---|---|---|---|
| gpt-4o | - | 99.99% | 605.0ms | 1.0x | 1.57 | 1.0x |
| gpt-4.1-mini | 64.5% | 99.93% | 484.0ms | 1.25x | 0.25 | 6.21x |
| llama-3.1-8b | 53.8% | 99.98% | 126.0ms | 4.80x | 0.04 | 37.43x |
| llama-3.3-70b | 83.7% | 99.96% | 234.0ms | 2.59x | 0.49 | 3.22x |
| llama-4-scout-17b | 72.2% | 96.71% | 1392.0ms | 0.43x | 0.28 | 5.61x |
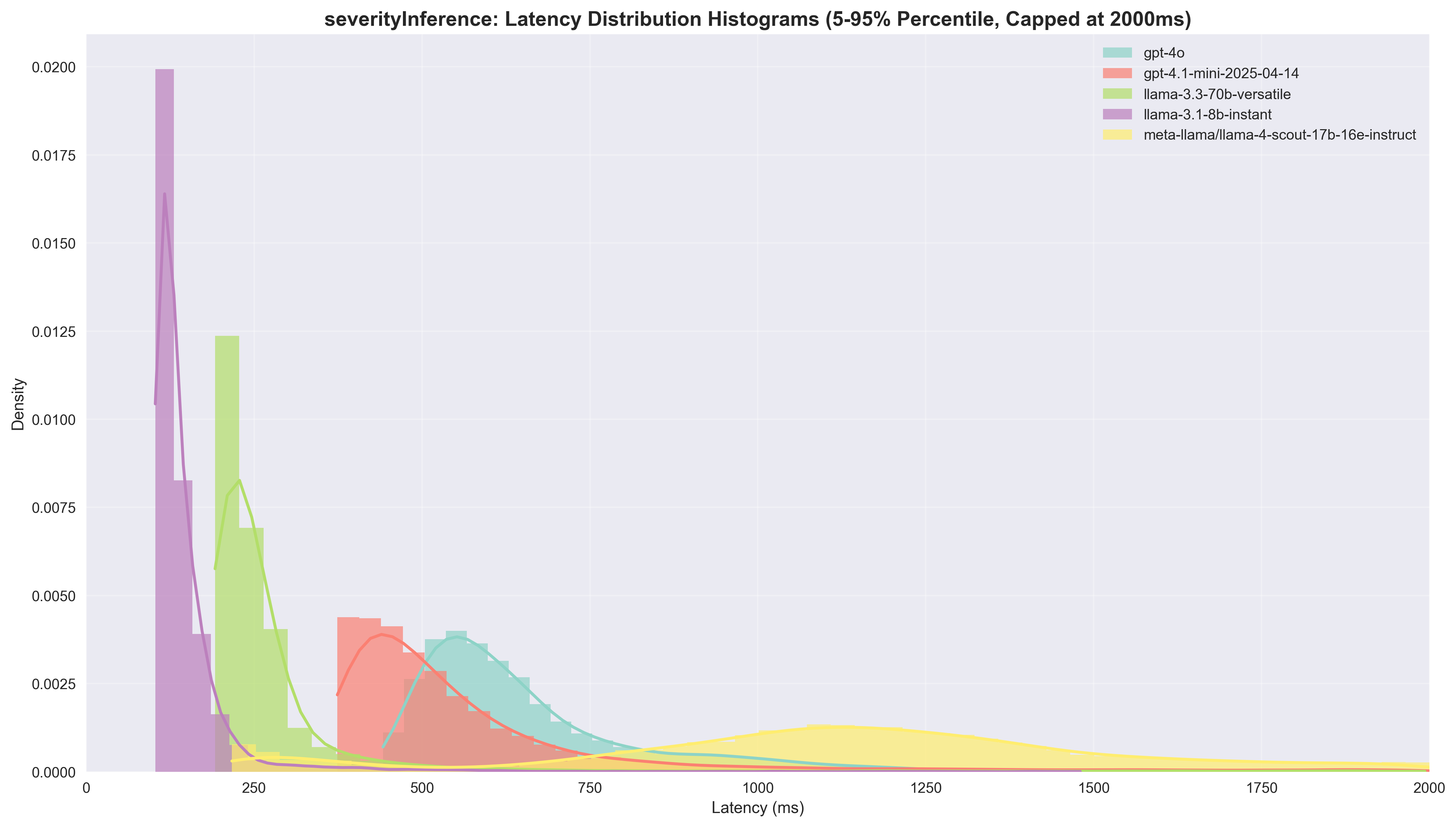
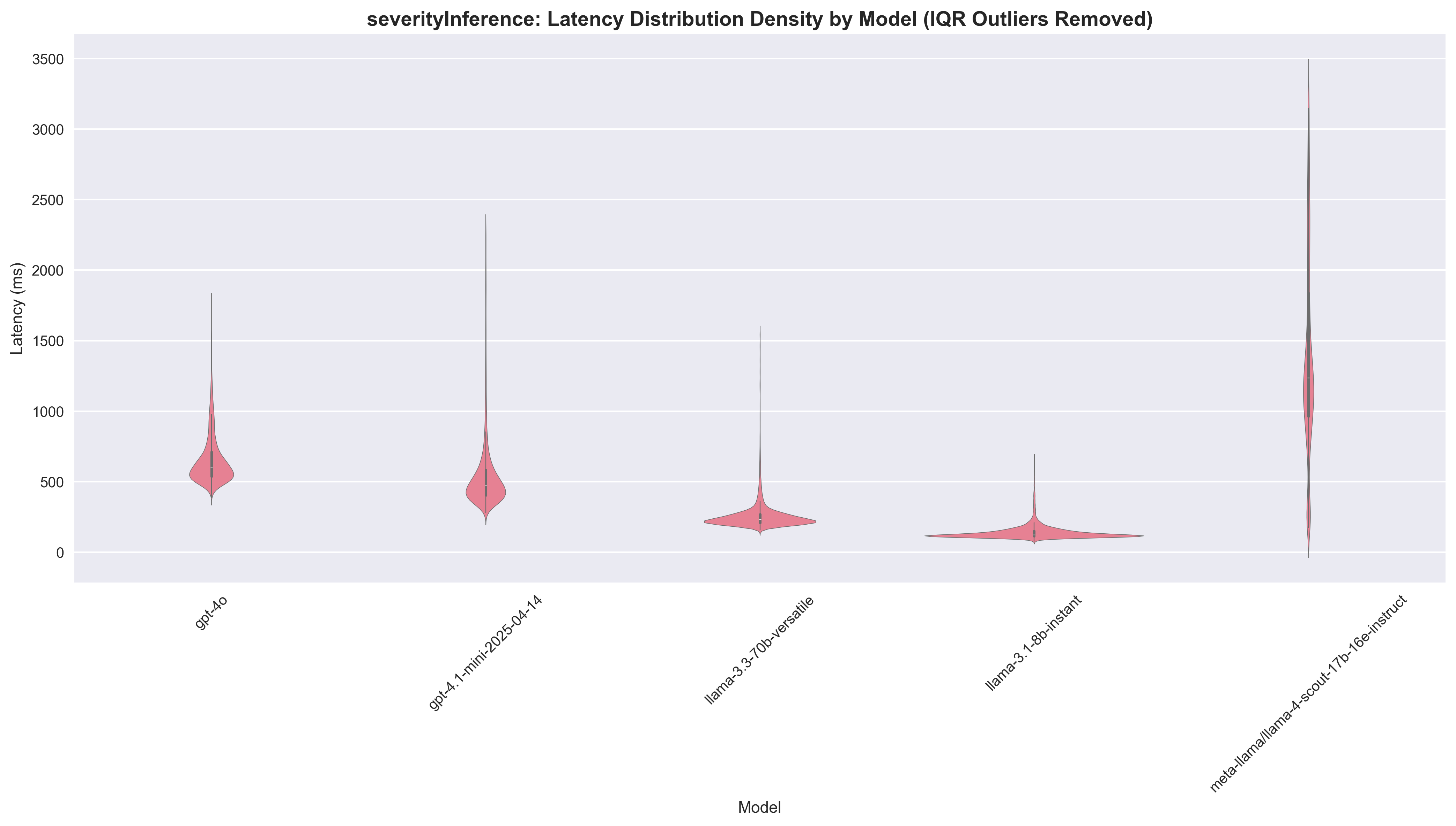
Key Insights:
- Llama 3.1 8B delivers exceptional speed performance with 4.80x speedup and the fastest absolute latency (126ms), making it the clear winner for speed. While coming in ~40x cheaper, we only achieve an agreement rate just above 50%
- Llama 3.3 70B provides solid speed gains at 2.59x speedup (234ms latency) while maintaining the highest agreement rate (83.7%) among alternatives. Paired with a 3x cost savings, it's a nice option
- GPT-4.1 mini offers modest speed improvement (1.25x) with reasonable latency (484ms), a 6x cost saving, but only 65% agreement rate
- Llama 4 Scout surprisingly shows slower performance (0.43x) with high latency (1392ms), making it unsuitable for speed-critical tasks
Manual Review: Looking at the manually obtained data, performance is pretty similar for all models, with GPT-4o coming out on top.
Recommendation: For speed-focused severity inference, Llama 3.1 8B is the clear winner with its 4.80x speedup and 126ms latency. If maintaining higher agreement rates is critical, Llama 3.3 70B offers a good balance with 2.59x speedup while keeping agreement above 80%.
Asset ID Inference
| Model | Agreement Rate | Success Rate | Median Latency | Speedup vs GPT-4o | Cost per 1K ($) | Cost Ratio |
|---|---|---|---|---|---|---|
| gpt-4o | - | 99.99% | 593.0ms | 1.0x | 1.13 | 1.0x |
| gpt-4.1-mini | 88.0% | 99.91% | 533.0ms | 1.11x | 0.18 | 6.28x |
| llama-3.1-8b | 55.1% | 100.00% | 123.0ms | 4.82x | 0.03 | 35.31x |
| llama-3.3-70b | 93.0% | 99.97% | 220.0ms | 2.69x | 0.38 | 3.01x |
| llama-4-scout-17b | 88.6% | 98.43% | 372.0ms | 1.59x | 0.16 | 6.98x |
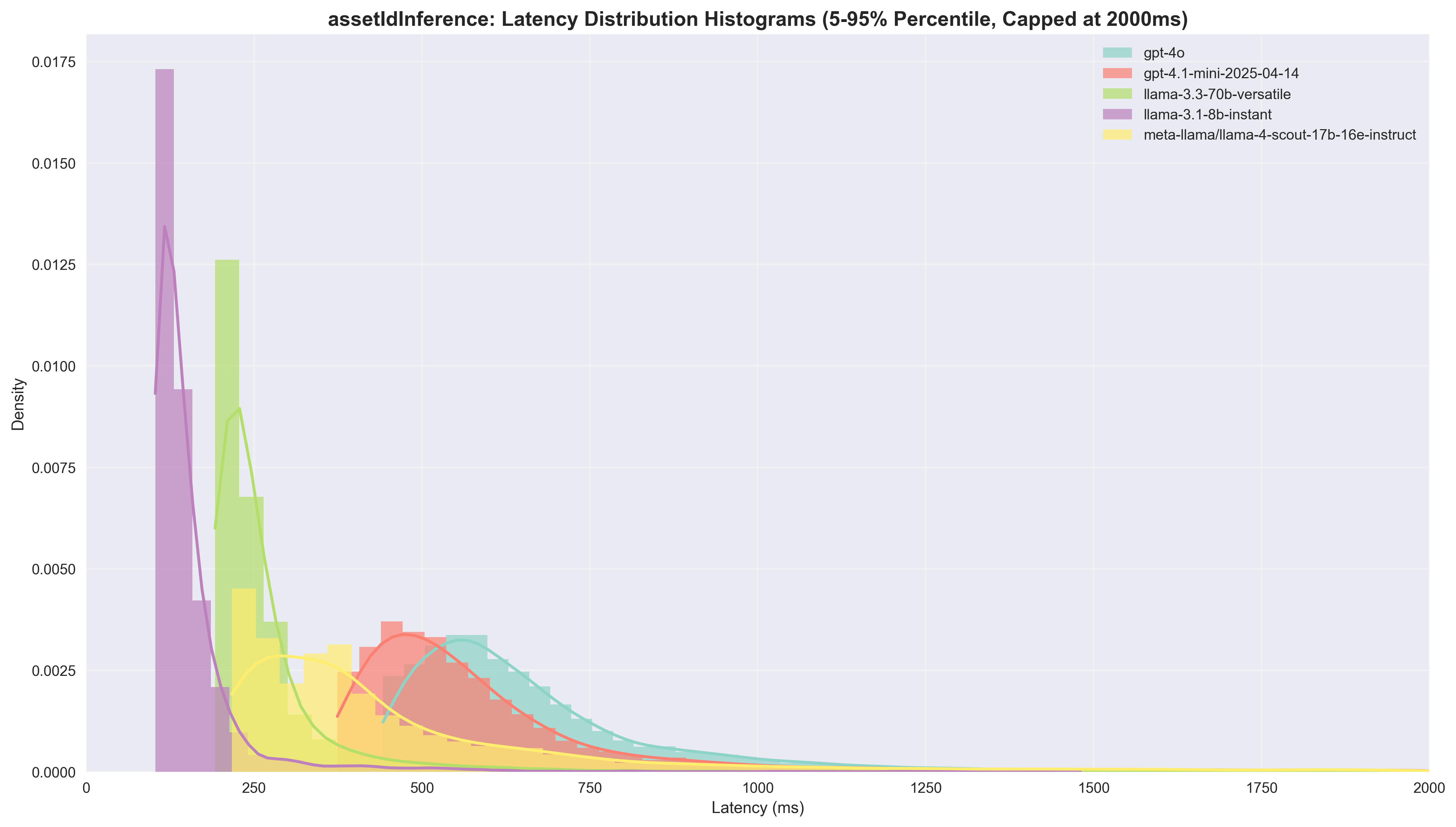
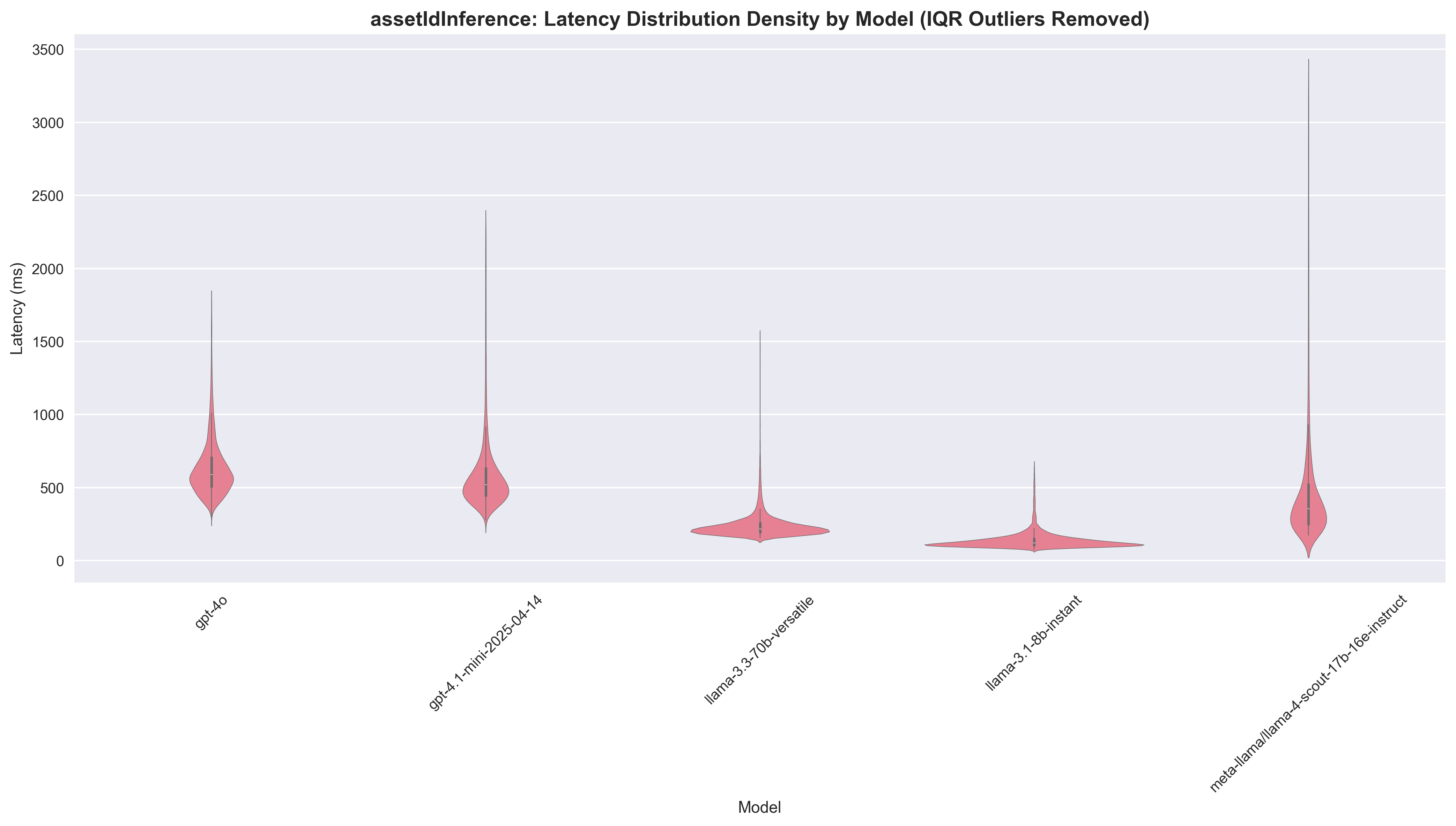
Key Insights:
- Llama 3.3 70B delivers the best balance with 93% agreement rate (and 0.95 in manual review), 2.69x speedup, and 3x cost savings, making it the standout performer for asset ID inference
- Llama 3.1 8B offers exceptional speed (4.82x speedup, 123ms latency) and massive cost savings (35x), but suffers from poor agreement rate (55.1%) and manual review score (0.55)
- GPT-4.1 mini provides minimal speed improvement (1.11x) but maintains high agreement (88%) and excellent manual review performance (0.95) with 6x cost savings
- Llama 4 Scout shows perfect manual review performance (1.00) with moderate speed gains (1.59x) and good cost savings (7x), though agreement rate is similar to GPT-4.1 mini at 88.6%
Manual Review: The manual review scores reveal a clear performance hierarchy: Llama 4 Scout (1.00) > GPT-4o/GPT-4.1 mini/Llama 3.3 70B (0.95) > Llama 3.1 8B (0.55). This suggests that while Llama 3.1 8B excels at speed, it significantly underperforms in accuracy for asset ID extraction.
During manual review, it stood out that Llama 3.1 8B was making a lot of mistakes distinguishing the few-shot examples and the actual ticket data (returning my-project-123 instead of returning null). We can probably improve this through better prompt formatting.
Recommendation: Llama 3.3 70B emerges as the optimal choice, offering the best combination of high agreement rate (93%), solid speed improvement (2.69x), reasonable cost savings (3x), and excellent manual review performance (0.95).
Technical Details Inference
| Model | Agreement Rate | Success Rate | Median Latency | Speedup vs GPT-4o | Cost per 1K ($) | Cost Ratio |
|---|---|---|---|---|---|---|
| gpt-4o | - | 99.71% | 1914.0ms | 1.0x | 3.35 | 1.0x |
| gpt-4.1-mini | - | 99.91% | 3792.0ms | 0.50x | 0.58 | 5.78x |
| llama-3.1-8b | - | 99.11% | 334.0ms | 5.73x | 0.07 | 50.76x |
| llama-3.3-70b | - | 99.22% | 1026.0ms | 1.87x | 0.74 | 4.54x |
| llama-4-scout-17b | - | 97.21% | 1083.0ms | 1.77x | 0.22 | 15.23x |
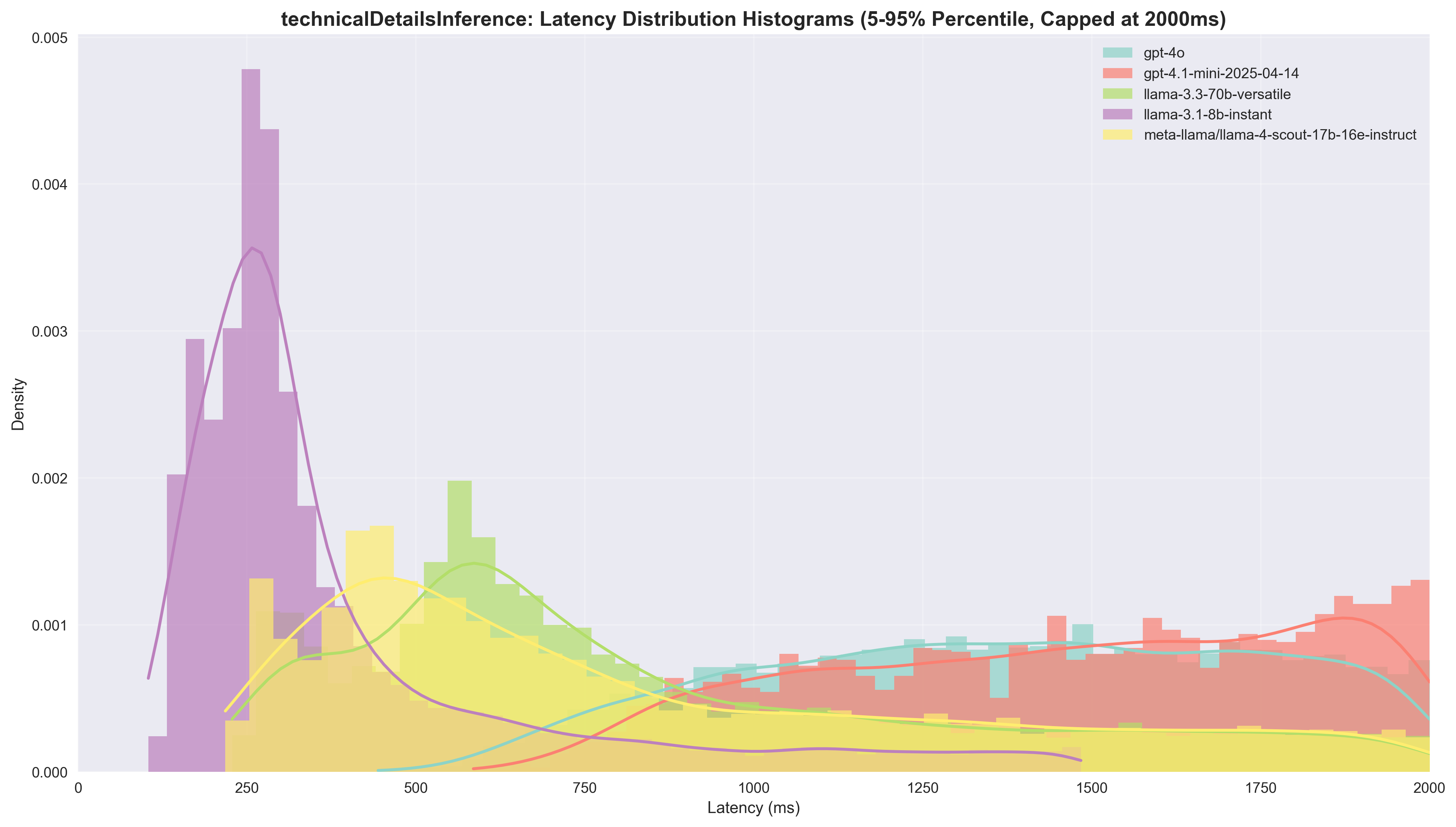
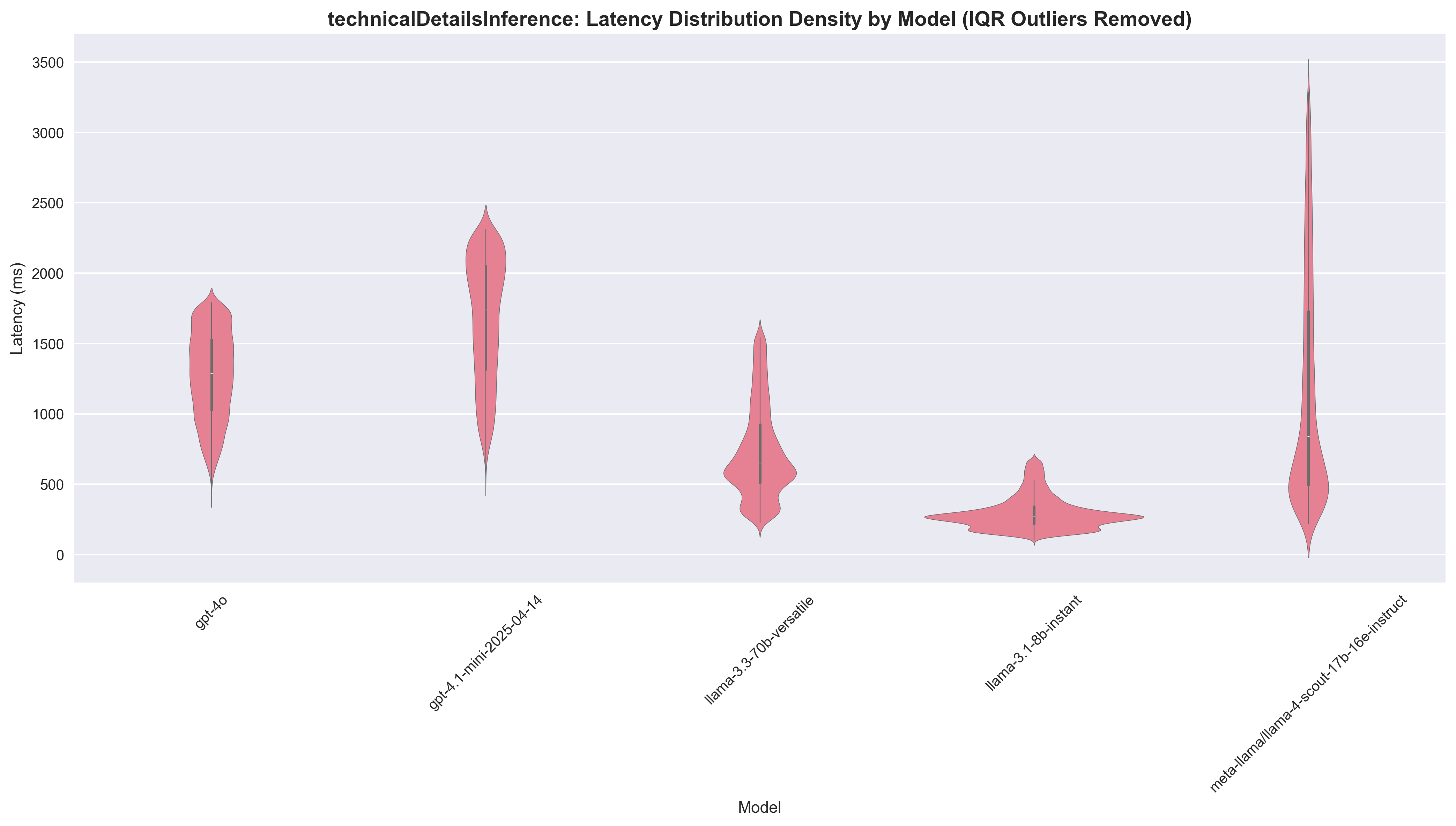
Technical Challenge: During manual review, we found that Llama 4 Scout struggled with following the instruction of returning null when it didn't detect any technical details, commonly returning things like "No Lambda function details are provided". While this can probably be solved through prompt optimisation, the other models didn't seem to suffer the same issue.
Recommendation: A tough call between Llama 3.1 8B and Llama 3.3 70B - one offering top-of-the-line performance, while the other offering another 3x speed gain. While we can probably squeeze out more performance through some kind of tuning of prompts, hyperparameters, or even supervised fine-tuning, we will recommend Llama 3.1 8B.
Architectural considerations
Our inference pipeline has inherent dependencies:
- Technical details inference depends on product inference (Platform → Product → Technical Details)
- Product inference, in turn, depends on platform inference (Platform → Product)
- Asset ID depends on platform inference (Platform → Asset ID)
- Severity inference is independent
Total latency formula:
max(
latency(platform) + latency(product) + latency(technical_details),
latency(platform) + latency(asset_id),
latency(severity)
)Since technical details inference has the highest individual latency, optimising this chain provides maximum impact. To decrease the impact of the latencies on each other, we propose to split the endpoint into three independent endpoints that return results as they become available to fully optimise the latency.
Anecdotal evidence from manual review
Improved ticket quality
Throughout this (and past) manual review, we've seen tickets where relevant technical details seem to be added just at the end before submission - as a way to satisfy our AI overlords. While we didn't deep dive on this pattern (yet), it's some encouraging anecdotal evidence that the system is successfully reaching its goal of guiding customers to provide comprehensive information.
Detecting "hidden" details
While it might be hard for a human to extract the correct asset ID from some tickets, CaseIQ successfully extracted asset IDs... from URLs! This demonstrates the system's ability to identify relevant information even when it's not explicitly highlighted by the customer.
Tickets with limited information
We observed that tickets where too little input was provided, led to nonsensical outputs, potentially confusing the customer. We should consider including a minimum token threshold or a classifier that determines if it makes sense to start inference. Adding this to future work!
The conclusion
Based on comprehensive analysis of latency, cost, accuracy, and architectural constraints, our overall recommendation is to:
- Use Llama 3.3 70B for platform (249 ms, 2.3x speed-up) and product inference (406 ms, 2.1x speed-up)
- Opting for Llama 3.1 8B would mean 334 ms for technical details, bringing the total to 881 ms (141 + 406 + 334), achieving a ~4x total speed-up (from ~3s before). Since technical details are not fed back directly to the customer, we think the performance trade-off is acceptable and we prefer this approach
- Opting for Llama 3.3 70B would mean 1026 ms for technical details, bringing the total to 1573 ms (141 + 406 + 1026), achieving a ~2x total speed-up (from ~3s before)
- Use Llama 3.3 70B for asset inference (220 ms, 2.7x speed-up): Llama 3.1 8B showed too many hallucinations, although we are confident it can do better with some polished prompting in the next iteration
- Use Llama 3.3 70B for severity inference (234 ms, 2.6x speed-up): the low agreement rate of Llama 3.1 8B prompted us to choose the bigger Llama model here. It won't affect the overall latency of the whole product (since the first chain will still be slower) and severity impacts the day-to-day of our engineers quite heavily since it is tied to our SLAs and SLOs
The total median latency would be the maximum of:
- 249 ms + 406 ms + 334 ms = 989 ms (platform + product + technical details)
- 249 ms + 220 ms = 469 ms (platform + asset ID)
- 234 ms (severity) = 989 ms total
While before (with GPT-4o):
- 571 ms + 851 ms + 1914 ms = 3336 ms (platform + product + technical details)
- 571 ms + 593 ms = 1164 ms (platform + asset ID)
- 605 ms (severity) = 3336 ms total
This represents a 3.4x overall speedup, a 30-50x cost reduction across 3 out of 5 tasks (the other 2 tasks benefit from a 3x cost reduction) - balancing out to an average expected 93% cost saving, while taking an acceptable performance hit.
Key takeaways
My takeaways from this project are that significant latency improvements in production AI systems are achievable through careful provider and model selection as well as architectural optimisation. While we aimed to reduce latency (which we did from 3+ seconds to sub-second response times), we got a nice cost reduction (of a few orders of magnitude!) for free. Another take-away is the importance of manual review - since we're dealing with humans and text, there is usually nuance that can't be captured using strict comparison (although that goes for the initial assessment as well - we're just assuming our baseline is correct here).
Looking ahead, we plan to implement the recommendations and architecture changes outlined in this analysis. We also want to brainstorm and implement feedback mechanisms that put our engineers in the loop for further model evaluation and capturing wider feedback. Prompt optimisation represents another significant opportunity for enhancement; both through shortening prompts to get better Groq response times, as well as tuning them to the specific models we decided on in this analysis. Finally, we're considering potential fine-tuning approaches that could yield further performance gains tailored to our specific use case and domain requirements.
For questions or comments about methodology or implementation details, feel free to reach out.