Ever wondered how "much" internet we have? While (as usually) the answer depends on "how do you want to measure it", according to Netcraft we have about 1.25 billion websites (June 2025). Statista estimates that we created, consumed and stored 149 zettabytes in 2024. That's 149 sextillion bytes (149,000,000,000,000,000,000,000 bytes), 149 000 exabytes or 149 billion terabytes. A. lot. of. data.
Full table of contents:
How much of that data is consumed by us, the flesh and blood human, you ask? Well, since 2024, you'll be happy to hear, less than half! Bot traffic accounted for 51% of all web traffic, according to 2025's Imperva Bad Bot Report. Malicious bots made up 37% of all traffic.
And how does the internet consume "us", humans? According to the Digital 2025 flagship report, the average user spends 6 hours and 38 minutes on the internet each day. Combining that with 5.56 billion internet users (see page 52), that means over 36 billion human‑hours/day. A. lot. of. time.
But before we get distracted, back to the topic of the day: bots and (malicious) internet users. One of our customers at DoiT I have the pleasure working with is active within the cybersecurity market. In their activities, they concentrate on Attack Surface Management (ASM) in which discovering a client's digital publicly exposed assets is a key activity. As part of our engagement, we looked at applying the AWS latest technologies to help them on their mission of protecting their clients. Having humans manually navigating this vast and dynamic attack surface is an impossible task. This is where autonomous AI agents come in as they can tirelessly explore digital assets, mimicking human researchers but at a machine's scale and speed.
TLDR; 🎯
In this article, I'll walk through how we built a production-ready Attack Surface Management (ASM) agent that can autonomously browse the web to discover and analyse security vulnerabilities. We'll explore:
- The complete architecture combining AWS Bedrock, Strands Agents, Model Context Protocol (MCP), and Bedrock AgentCore
- Deep-dive into agent frameworks, reasoning models, and the latest in agentic AI patterns
- How to equip agents with tools (browser automation via Playwright/AgentCore, filesystem operations via MCP)
- Grounding your agent with external knowledge using Bedrock Knowledge Bases and the CVE database
- Deploying to production with AWS Fargate and the new managed Bedrock AgentCore runtime
- Observability and monitoring through Langfuse and CloudWatch
The code is available on GitHub.
What we built
We looked at Agent definitions in my previous blogpost, and AWS also includes a definition in their docs, in this case for "Agent Loop":
The agent loop is a core concept in the Strands Agents SDK that enables intelligent, autonomous behavior through a cycle of reasoning, tool use, and response generation.
A bit more wordy, but the essence remains the same. In our case the flow looked something like this:

In this post, I'll explore how we helped our customer with an AI agent that can actually browse the web, look at the architecture needed for doing so on AWS, take a closer look at Strands Agents (and do some comparisons with ADK here and there), and how to deploy all of this to production.
The complete tech stack
The different components making up the whole application are:
| Component | Technology | Description |
|---|---|---|
| Foundation Model | Amazon Bedrock | Managed service providing access to 100s of large language models |
| Agent Framework | Strands Agents | SDK for building and deploying production-ready, multi-agent AI systems |
| Tooling | Model Context Protocol (MCP) | Open protocol for connecting LLMs to external tools and data sources |
| Retrieval | OpenSearch via Amazon Bedrock Knowledge Base | Vector store for semantic search and retrieval-augmented generation (RAG) |
| Runtime | AWS Fargate, Amazon Bedrock AgentCore | Serverless platform for running (agent) workloads without infrastructure management |
| Infrastructure as Code | AWS CDK | Cloud Development Kit for defining cloud infrastructure using familiar programming languages |
| Observability | LangFuse | Open-source platform for monitoring and evaluating LLM applications |
But what would a good blogpost be without a nice architecture diagram?
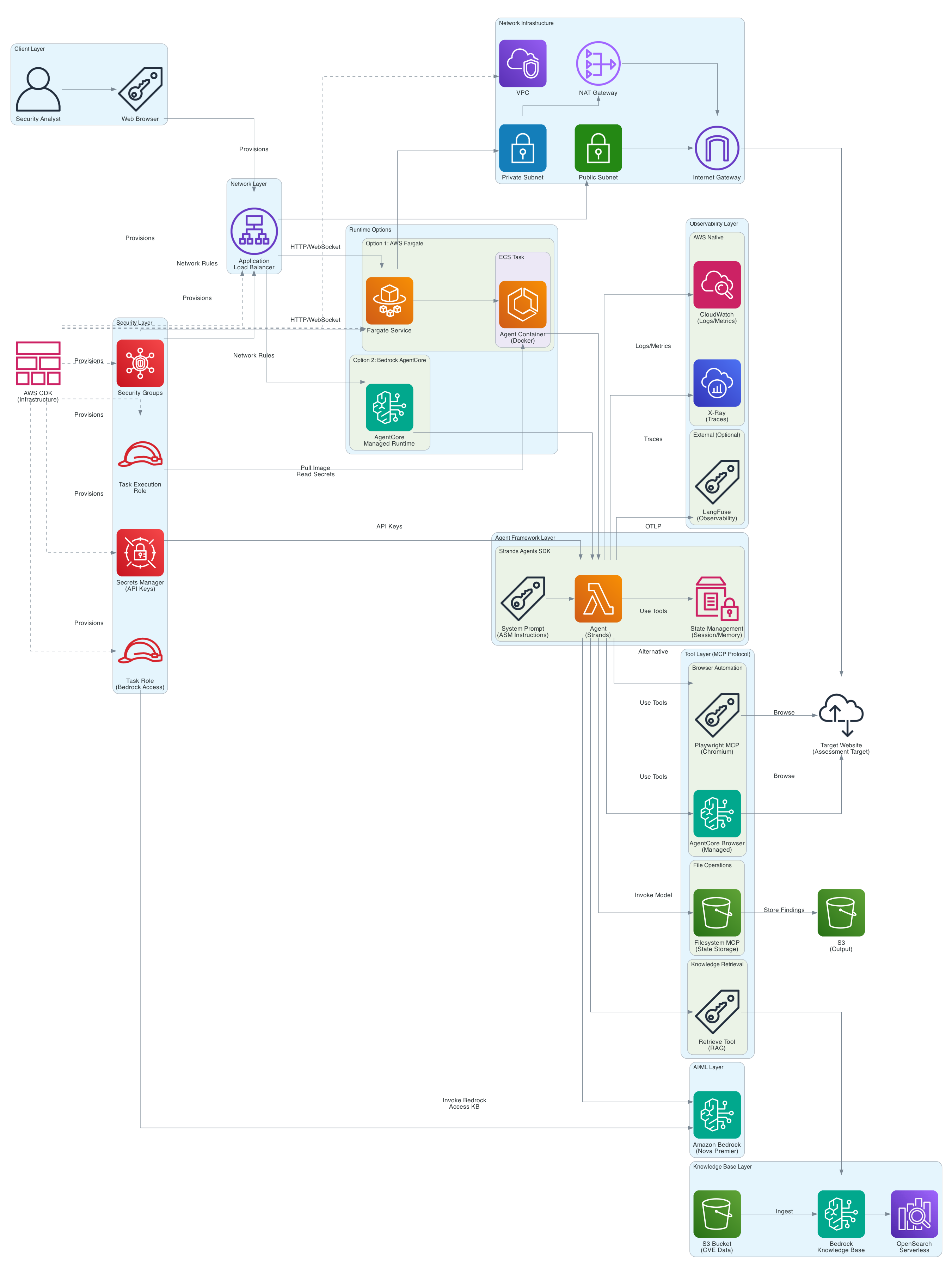
Protip: checkout my colleagues article on using Strands and MCP to generate your diagram!
But without further ado, let's dive one level deeper into each of these components!
Diving deeper: building blocks 🔍
Let's work our way through the problem working back from what we want to deliver: an LLM-driven agent that goes out to a given domain, discovers what is exposed, and looks for what is prone to an attack.
Agent framework: Strands Agents
I started building with InlineAgents which was announced end of 2024. But documentation and support seemed rather thin and buried inside the samples repo and around the same time the first version of Strands Agents was released. Given it had more documentation and seemingly investment as well, it seemed like the healthier choice. Included in that were clear pathways to deployment and a clear focus on observability and evaluation.
In the meantime Strands Agents has evolved beyond the v1.0 launch in mid-July and has a flashy website. But it comes with a lot of goodies - I'll highlight a few that jumped out to me in this section and throughout the sections to follow where appropriate.
Like ADK, Strands Agents keeps track of your conversation history through messages (events in ADK) and maintains state (as key-value storage). Persistence is available through FileSessionManager and S3SessionManager for local or remote storage respectively. ADK provides similar options through their MemoryService with an in-memory and remote implementation.
Something where the two frameworks diverge is tools to do context engineering. As I discussed in the ADK post, as history grows, managing context becomes increasingly important. While still missing in ADK at the time of writing, Strands Agents comes packed with SlidingWindowConversationManager by default which will purge a fixed number of recent messages. More interesting though is the SummarizingConversationManager which will summarise your context with the help of an LLM and is fully configurable. For the adventurous among us, there's the option to implement an apply_management (running at the end of each agent cycle) and reduce_context (running when your context window is exceeded) function in your own ConversationManager. Head to the docs to learn more!
More customisation is possible in both frameworks through what is called hooks in Strands Agents and callbacks in ADK. As we know, an agent is an event-driven system, and essentially, it allows you to plug-in some custom code everytime a certain event takes place. Strands defined slightly more events than ADK: 8 vs 6.
In the multi-agent area, Strands also supports Agent2Agent (A2A) protocol and Agents as Tools. The latter is implemented just through wrapping your agent with the @tool decorator, while in ADK you will use AgentTool class. While ADK provides you with a set of common patterns, Strands gives you Graph (with recommended topologies) and Swarm (autonomous coordination) primitives to work with. A point of confusion in this area are the Workflow Agents and Agent Workflows. While in ADK it means introducing more determinism into your execution flow, AWS documentation talks about:
An agent workflow is a structured coordination of tasks across multiple AI agents, where each agent performs specialized functions in a defined sequence or pattern
Seemingly, the documentation talks about a workflow as a sequence of tasks (which in my head would make it an instance of a Graph), but later on in the documentation a Workflow Tool gets introduced which looks more like a dynamic task scheduling system. I hope this part gets clarified in the documentation soon.
Overall, Strands Agents seems a solid choice if your infrastructure is AWS heavy, as pointed out in AWS own comparison and considerations page.
(Reasoning) models 🧠
But before we digress too far from our initial goal, let's talk about the other components of our architecture, starting with the brain of our agent. The ability of this brain to "think" or "reason" has evolved rapidly.
As mentioned in my last post, Andrej Karpathy has a great video on how modern LLM systems are created. While a thorough literature review would have me digress too far again (and I hope to deep-dive on this in another post at some point), I'll give a quick overview of my current understanding.
The first step came when we started prompting LLMs to produce "reasoning traces" before giving an answer, achieving state-of-the-art results: Chain-of-Thought (CoT) prompting. This technique got taken further with Tree of Thoughts (ToT) in which multiple reasoning paths were considered, and Graph of Thoughts (GoT), in which reasoning is modelled as a graph in which thoughts are vertices and relations are edges, enabling merging of related thoughts, feedback loops, showing stronger global reasoning and cost reduction. In other work from Google, LLMs get asked to output intermediary steps (not unlike a scratchpad), or generate multiple reasoning paths after which the most consistent one get chosen by majority vote (Self-Consistency Improves Chain of Thought Reasoning in Language Models). From University of Washington, the model asks itself questions, further improving results.
These methods help surface the reasoning abilities latent in pre-trained models. But to actually improve reasoning quality, researchers started teaching models how to reason better. OpenAI showed that process supervision (feedback for each intermediate step) improves performance, and mention it in the release blogpost of their first reasoning model o1 about a year ago, while Google lets a model improve itself by learning from its own generated reasoning. The DeepSeek team showed that emergent reasoning behaviour is possible through reinforcement learning alone.
Apart from thinking, an agent also needs to be able to "do stuff". That's where ReAct comes in, a very important paper in the advent of agents, where LLMs were asked to generate both reasoning traces and actions in an interleaved manner (which is essentially the agentic loop). In related work Meta AI proposed ToolFormer, where an LLM was trained to decide which tools to use when in a self-supervised way.
All of the above (and probably a lot more) enables us to program a simple agent with a few lines of Python code, like I did for our ASM agent:
all_tools = [retrieve]
with playwright_mcp_client, filesystem_mcp_client:
playwright_tools = playwright_mcp_client.list_tools_sync()
filesystem_tools = filesystem_mcp_client.list_tools_sync()
all_tools.extend(playwright_tools + filesystem_tools)
agent = Agent(
model=bedrock_model,
system_prompt=system_prompt,
tools=all_tools,
)As the attentive reader might have spotted in the above code, I used a variable named bedrock_model, which means - YOU MIGHT HAVE GUESSED IT - the model I used was hosted on Amazon Bedrock. Strands Agents has a big section on "Model Providers" ranging from the popular closed and open models (OpenAI, Anthropic, MistralAI, Llama API, ...) to tooling to run models locally (llama.cpp, Ollama, ...). Since the customer was already using AWS and Bedrock provides easy access to the state-of-the-art foundation models from leading providers through a unified API, it was a no-brainer to start here.
Now that we have a reasoning brain for our agent, we need to give it hands - the tools it needs to actually interact with the web and gather information.
Tool use and Model Context Protocol (MCP) 🛠️
While Strands Agents follows a model-first design, tools still play a central role in being able to act and in grounding the model as part of fulfilling the agent's goal.
This works through a tool registry that gets initialised at agent creation time. Defining which tools are available to the agent is as simple as passing a list as you can see in my agent definition above.
Strands supports a multitude of tools:
- Python tools (most commonly through decorator)
- Through MCP (see below for more)
- A huge list of community tools. In building the agent, we used the
retrieve, and later on the AgentCore Browser. Another personal highlight for me is the handoff_to_user tool in case you want to get a human-in-the-loop (also in ADK since v1.14).
As the documentation points out:
Language models rely heavily on tool descriptions to determine when and how to use them. Well-crafted descriptions significantly improve tool usage accuracy.
We can inspect such examples by looking at the source code, e.g. for retrieve if we need inspiration for our own tools. In case of using tools through MCP, like we did e.g. for the filesystem tools, we need to take a look at the server implementation. It's always good to take a look to avoid Tool Poisoning Attacks
Bear in mind that it is best practice to explicitly limit the tools to only the ones you need. All the information (tool description, schema, ...) get passed to the LLM on each invocation, growing your context window. It also avoids letting your agent suddenly start calling tools that were added to the MCP server after you initially defined the agent, leading to potential vulnerabilities. See also Drew Breunig's great article on "How to Fix Your Context", specifically the section about Tool Loadout
You are able to specify an execution strategy for your tools as well: by default, tools get executed in parallel, but that can be changed to sequential.
As you might have spotted, we used two MCP servers which we'll discuss in the next two subsections. We also used the retrieve tool, which we'll discuss in the next section.
Playwright
Microsoft has open sourced an MCP for Playwright. When I initially start experimenting for this project, I ran into the Browser Use project, and they were using (an adapted version of) Playwright, so I figured it was a good place to start.
But why not simple cURLs you ask. When we use a full browser, we get the full experience that comes with JavaScript execution: dynamically loaded content, user interaction and backend communication, getting the complete picture of the web application functionality (and potential vulnerabilities). It allows us to simulate user interactions like logging in, navigating through clicking buttons and submitting data through filling out forms. Through these interactions, we can uncover assets not present in HTML. On top of that, we can browse statefully, handling sessions and cookies.
It comes with the option to browse headed, which is great during the initial development to see how your agent is behaving. Once we gained some confidence and are ready to deploy to production, a headless configuration might suffice.
At the start of August however, AWS announced Amazon Bedrock AgentCore which comes with its own Browser Tool, making my life even easier. It provides a zero-management browser solution, that can scale easily, runs in an isolated environment (which wasn't the case in my first architecture), and integration with several AWS services like IAM, CloudTrail, and CloudWatch for access management, tracking, and monitoring. Lucky enough, I was able to update the code to use this with minimal changes:
# importing the new tool
from strands_tools.browser.agent_core_browser import AgentCoreBrowser
# updating the list of tools from MCP to AgentCoreBrowser
all_tools = [retrieve, AgentCoreBrowser().browser]Filesystem
To keep track of pages visited, actions tried, and vulnerabilities found, I decided to use the filesystem MCP for filesystem operations that is part of the modelcontextprotocol repo. There are probably more robust solutions for state management, but for a first implementation this did the trick. I provided some guidance on where to keep track of state, what to save in our "security findings database" and how to keep track of the state of interactions in the system prompt, as well as a stopping condition.
Grounding and retrieval-augmented generation (RAG) 📚
In order to keep our agent's knowledge up-to-date with the latest and greatest in the security landscape like newly discovered vulnerabilities, we decided to equip it with a database of known vulnerabilities. We demonstrated this through grounding the model in the "Common Vulnerabilities and Exposures" database which is open source available in the CVE Project repository. Through enabling our agent with the retrieve tool, we enabled it to rely on external and up-to-date knowledge queried at runtime.
For this, we leaned on Amazon Bedrock Knowledge Bases, a service that helps a lot with the heavy-lifting setting up such workflows: it takes care of parsing, chunking, and embedding your data, and serves the relevant data to your agent. It's backed by OpenSearch Serverless, Pinecone, Redis, MongoDB, Aurora, as well as the recently announced S3 Vectors.
We did some pre-processing to filter out irrelevant vulnerabilities and split the files to cope with Bedrock Knowledge Bases' 50MB file size limit - more on that in the repo.
With our agent now capable of accessing knowledge and storing findings, the next challenge was taking it from a local development environment to a production-ready system that could operate reliably at scale.
Productionising the whole thing 🚀
The teams behind Amazon Q Developer and AWS Glue have been using Strands Agents in production for a while, so why wouldn't we? Let's look at how we brought this whole set-up from local to the cloud.
Deployment
For deployment, the options in the documentation are heavily AWS biased (think EC2, EKS, Fargate, Lambda) as also highlighted in the agent framework comparison, but I believe deployment shouldn't be an issue on different clouds with similar offerings (at the end of the day we are just looking for memory and compute cycles). However, we wanted to stay within the AWS ecosystem since that's where our customer is, and for that reason experimented with two of the most scalable and managed solutions on offer: Fargate and Bedrock AgentCore.
Fargate is AWS version of "bring your container and forget about servers and scaling", hence you will find a Dockerfile in the repo. It installs the necessary dependencies, including the MCP servers and browser dependencies. I included a docker-compose as well to test locally. Once you're happy, you'll want to push them to ECR (Elastic Container Registry). There is a cdk folder taking care of setting up the necessary infrastructure (think Fargate Service, Load Balancer, VPC, IAM roles etc) and I recommend taking a look at the README for more information.
The other option is through a relatively recent adition to the Bedrock suite of products: AgentCore. With relatively few code changes, we managed to replace the Playwright browser with the AgentCore managed browser which illustrates the composability and building blocks Strands Agents gives you brilliantly.
AWS also opensourced a starter toolkit for AgentCore. With a simple agentcore configure and agentcore launch you're off to the races (or should I say cloud?). Check out the AgentCore Runtime Quickstart. In order for me to use the fully managed runtime that abstracts away the container as well (and thus not spinning up a separate filesystem MCP), I refactored the state slightly to use native state instead of saving everything to disk - but logic stayed more or less the same. No fiddling with CDK, VPCs, and load balancers in this case, just nice and easy deployment.
A last tip (one that I haven't tried myself but am very keen to): there is an AWS Bedrock AgentCore MCP Server - plug this into your vibe coding set-up and your agent will potentially build itself! Jokes aside - it will help you with documentation and best practices in your building journey :)
Observability and evaluation 📊
The Strands Agents documentation has a whole section on observability and evaluation which is great.
It outlines the classic software engineering observability with traces, metrics, and logs and applies them to AI workflows with suggestions to analyse edge cases and collecting traces to do evaluation, benchmarking, and fine-tuning. An agent comes out-of-the-box with metrics about token usage, cycle duration, and some tool metrics that give you insight into failure rates of the tool. Just like ADK, Strands comes with native integration with the industry standard OpenTelemetry, giving you the flexibility to route that data to AWS X-Ray, but also to alternatives like Jaeger or Langfuse.
Lastly, it includes a discussion about why investing in telemetry makes sense: of course, to know about when your agent breaks, but also to keep track of costs & usage trends, as well as customer satisfaction. The latter goes into agent evaluation, analysing failures, building ground truths, and using data to finetune. It has sections on test case categories, metrics to consider, and evaluation approaches.
In the first iteration, I integrated my agent with the observability platform offered by Langfuse. The set-up is super easy: just create an account and plug-in a few environment variables and you will start seeing traces appear in the platform. What you get is super helpful:
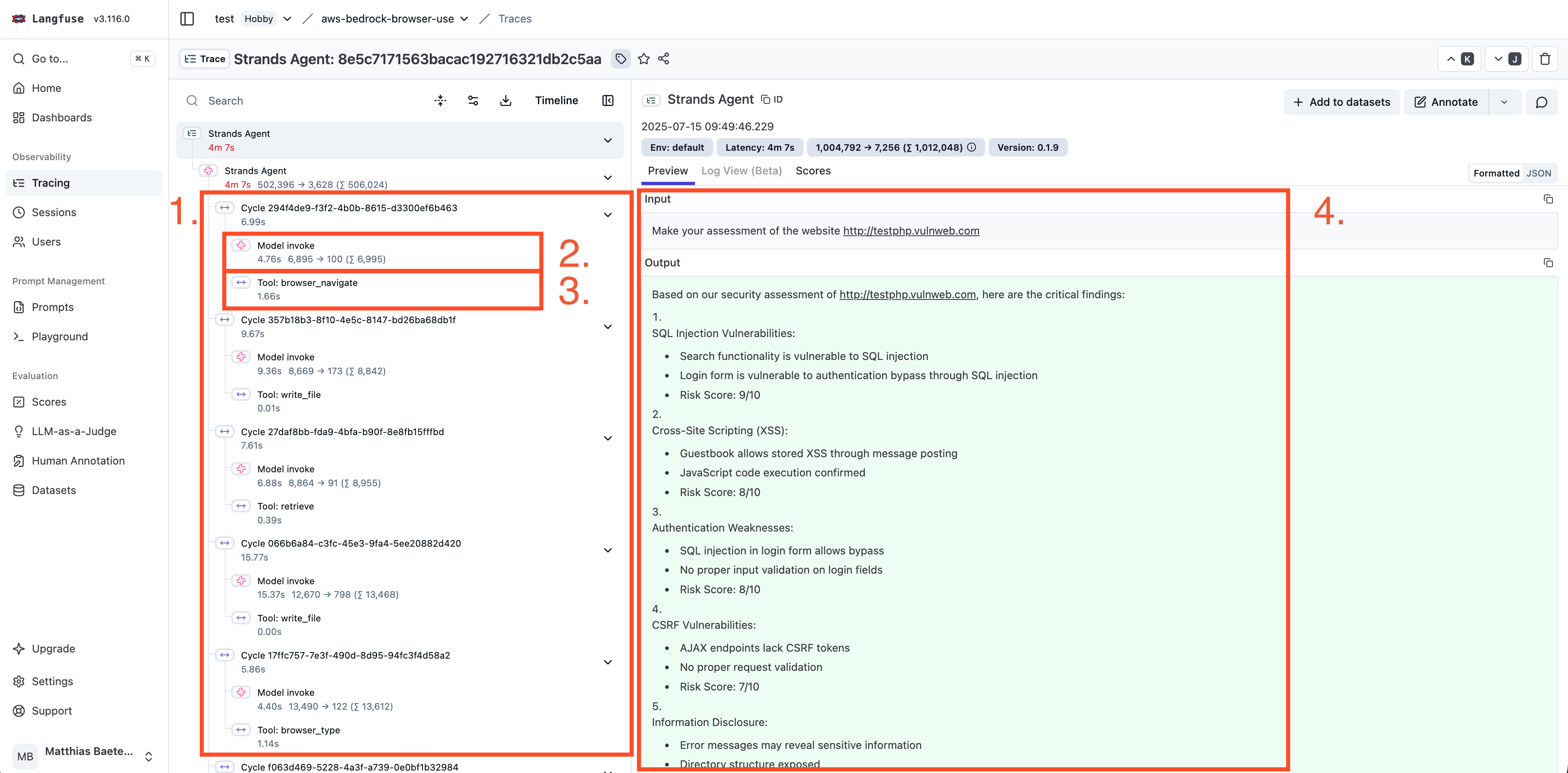
- All the loops your agent does while trying to reach it's goal
- LLM calls (with input and output) that are part of that loop (great to inform iterations on your system prompt and potentially tool descriptions). Notice also the total input and output tokens
- Tool calls (with input and output)
- Extra information for each of the components on the left that are selectable, in this case the goal I gave the agent and the output it generated (report with the vulnerabilities it has found)
It also includes latencies for each of the steps in case you want to optimise certain parts of your run.
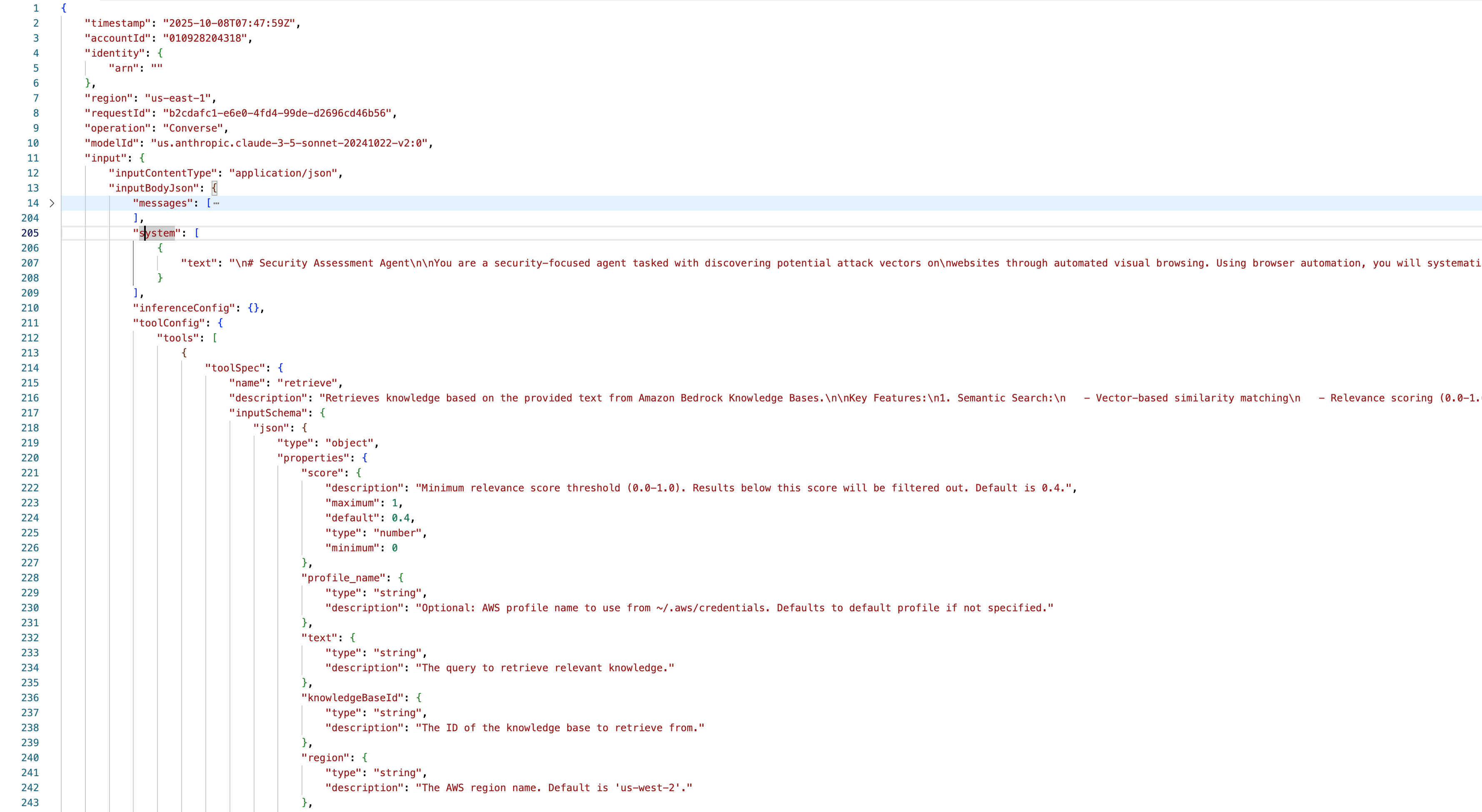
One thing I was missing is the full prompt (as we discussed above, not only user input gets passed to the LLM, but also the system prompt and tool descriptions). For that, I can recommend turning on Bedrock Model Invocation logging which showed me the whole context, including messages, system, toolConfig with different toolSpecs:
That being said, with the launch of AgentCore, we got another set of options, baked straight into AWS through AgentCore Observability. The AgentCore docs have a great quickstart guide and the steps are quite trivial, so if you prefer to consolidate everything into AWS and avoid external integrations, this is definitely the way to go! It looks something like this:
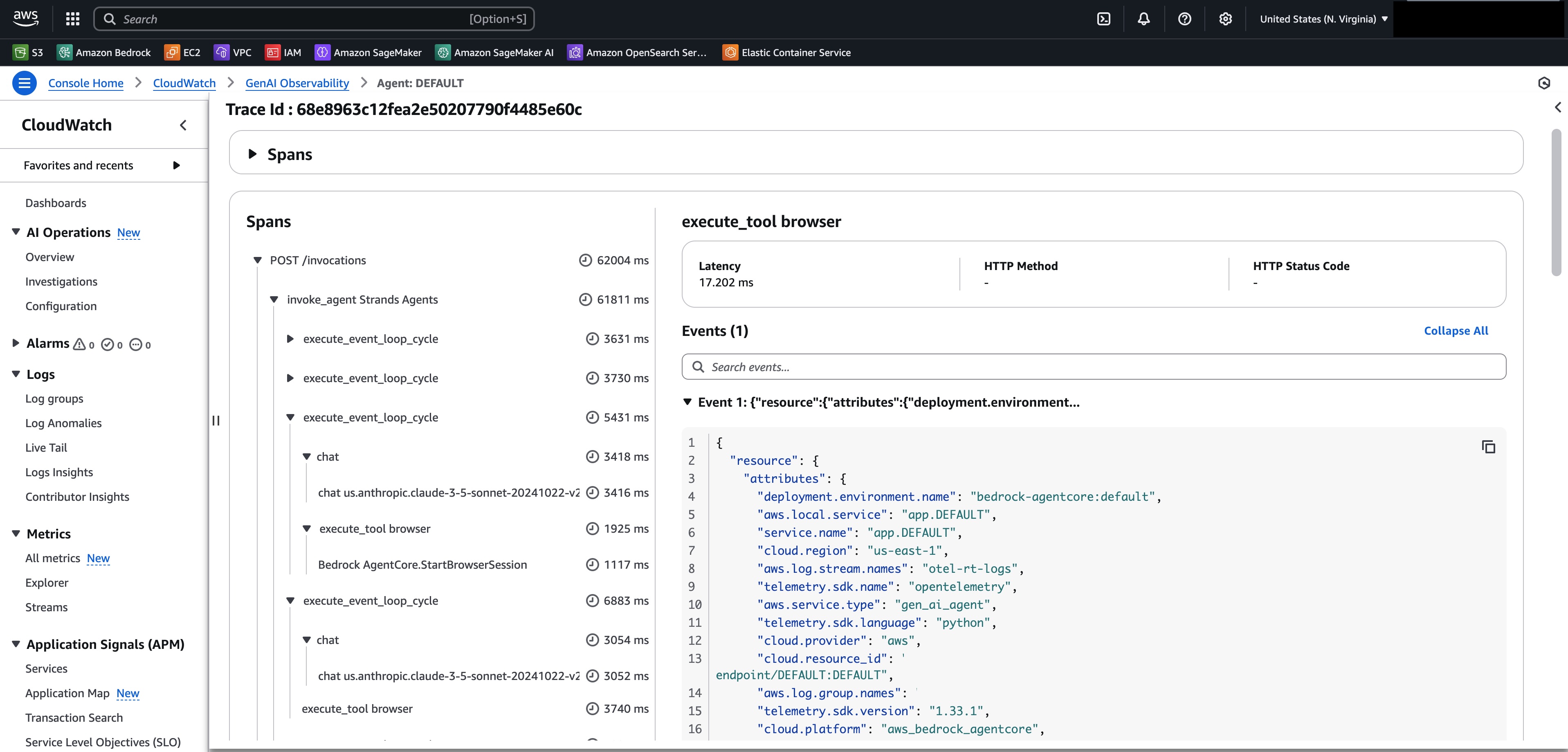
This way, everything (logs, metrics, and traces) are neatly stored in CloudWatch and you just need to keep an eye out on the GenAI observability page!
Conclusion and future work 🎬
Conclusion
We've come a long way from those staggering internet statistics to building our own intelligent agent that can navigate and analyze the web for security vulnerabilities. In this post, we built a production-ready Attack Surface Management agent using AWS Bedrock and Strands Agents, taking it from concept to a cloud-native deployment.
We walked through the complete architecture: from choosing an agent framework and understanding the latest in reasoning models, to implementing browser automation and grounding our agent with a knowledge base of CVEs. We then took it all the way to production with AWS Fargate and AgentCore, complete with proper observability through Langfuse and CloudWatch and sprinkled with some comparisons to ADK along the way.
When we unleashed our agent on testphp.vulnweb.com, a website designed to be vulnerable, it autonomously discovered and exploited several critical security flaws. Amongst others, it successfully performed a SQL injection to bypass the login, found and demonstrated both reflected and stored Cross-Site Scripting (XSS) vulnerabilities, and even identified that the site had been compromised and was redirecting to a defacement page. This test run proved that the agent can not only discover potential attack vectors but also validate them, providing concrete evidence of real-world risks.
Future work
While the agent works, there's still plenty of room for improvement that I would like to work on next:
- Proper context window management: right now we're relying on Strands' built-in
SlidingWindowConversationManager, but for our use-case we don't want to rely on the context window to keep track of what has been done, what needs to be done, and the intermediate findings. Instead... - We should design a better state management system: using the filesystem MCP (and later internal agent state) served as a quick prototype, but a production system demands better. A dedicated state management solution would enable more reliable tracking and comprehensive documentation of security findings.
- Proper evaluation: Right now, we're flying somewhat blind without a systematic evaluation framework. Building a test suite with known vulnerabilities, establishing baseline metrics, and implementing the evaluation approaches discussed in the Strands documentation would give us confidence that each iteration actually improves the agent's capabilities. Since this is a very domain-heavy exercise, I'll probably need to find some strong collaborators for that :)
The code for everything we discussed is available on GitHub and in the meantime, Amazon Bedrock AgentCore went GA as well, making it ready for your production use cases! Feel free to experiment, improve, and share what you build!