Another weekend, another agent. About 1 year ago, I put together a talk for I/O Extended in Kuala Lumpur, talking about how "Gen AI could be your cupid in the job market", exploring how we could leverage Retrieval Augmented Generation (RAG) for finding the most appropriate CVs given a job description:
Now in 2025, with a bit more experience in the LLM space and some more maturity (at least that's what I like to believe), I reckoned it would be a great idea to build something that could potentially be useful for myself instead... Hence I set off to build a CV builder agent!
Erwin Huizenga's post came just in time to help ease the coding pain a bit:
... but more on that later.
The goal of my endeavour was to make something useful, while exploring the Agent Development Kit (ADK) released by Google earlier this year at Google Cloud Next 2025:

as well as share some interesting bits and bobs I learned along the way; either from building them myself or from different reads across the World Wide Web. You might notice that some of my references are from the end of June or start of July. From that you might infer that's when I started writing and that it took >2 months to actually release this post... and you wouldn't be wrong!
Anyway. Diving in...
Full table of contents:
- Agent Development Kit (ADK)
- The journey from a single monolithic agent to multi-agent (and back?)
- Some learnings along the way
- Conclusion
Agent Development Kit (ADK)
(don't care about the theory, just want to see my over-engineered CV bot? I GOT YOU COVERED: click here to skip to the architecture)
Let's start with a little intro of what Agent Development Kit (ADK) is. In short, it's Google's take on building agents; and since everyone and their mum (LangChain had LangGraph for a while, Hugging Face launched smolagents, AWS launched Strands Agents SDK, OpenAI launched the aptly named Agents SDK, Microsoft has AutoGen out for a while, and we can go on and on) seems to be releasing an agent framework today, Google couldn't stay behind.
In the docs it gets introduced as:
Agent Development Kit (ADK) is a flexible and modular framework for developing and deploying AI agents. [...] ADK was designed to make agent development feel more like software development, to make it easier for developers to create, deploy, and orchestrate agentic architectures that range from simple tasks to complex workflows.
So let's take a closer look. What are AI Agents, really? How do I architect an agentic system? Does it make sense to "go multi-agent"? What does "rich tool ecosystem" mean exactly? And how do I move all of this from my local machine into the cloud?
AI Agents
There are a few AI Agent definitions floating around the community: Google has their definition:
AI agents are software systems that use AI to pursue goals and complete tasks on behalf of users. They show reasoning, planning, and memory and have a level of autonomy to make decisions, learn, and adapt.
while Wikipedia quotes Russell & Norvig's work "Artificial Intelligence: A Modern Approach" to define an agent:
Anything that perceives its environment and acts upon it
My personal favourite is from Simon Willison's blog, who in turn got it from Anthropic's Hannah Moran:
Agents are models using tools in a loop
which he recently updated slightly to:
An LLM agent runs tools in a loop to achieve a goal
I like them because it's simple, easy to understand and technically (quite) accurate for most Agent frameworks. Let's look at the agentic loop for ADK:
async def run_async(
self, invocation_context: InvocationContext
) -> AsyncGenerator[Event, None]:
"""Runs the flow."""
while True:
last_event = None
async for event in self._run_one_step_async(invocation_context):
last_event = event
yield event
if not last_event or last_event.is_final_response() or last_event.partial:
if last_event and last_event.partial:
logger.warning('The last event is partial, which is not expected.')
breakwhich looks a lot like this:
This is what they call "an agent." pic.twitter.com/cwgLtqySBr
— BURKOV (@burkov) July 10, 2025
Pretty simple, eh? Going one level deeper, looking at _run_one_step_async, we can see each step consists of:
- Pre-processing: any custom request pre-processing and tool preparation
- A call to an LLM
- Post-processing: execute any tool calls as well as handover to another agent
This code involves a lot of Events and an Agent is thus an event-driven system where we put an LLM in charge of handling them. Time to take a closer look at what these magical Events actually are!
Events
Events are the lifeblood of an Agent, and are essentially what's being passed around internally. If we equate the LLM to a brain, the tools to the body of the agent, the events would be the nervous system coordinating the two, passing around inputs to the brain (e.g. coming from the user, the tools, ...), as well as outputs (e.g. call this tool, say this phrase, ...), and internal messages (e.g. remember this, ...).
They are involved in the entire process from initiation of the agent until it "finishes"; which as you can see in the above run_async is determined by a "special" event.
The formal definition in the ADK docs is:
An Event in ADK is an immutable record representing a specific point in the agent's execution.
and it's defined in code here
Events can originate from multiple sources; a user input will generate an event (with author='user'), as well as the agent itself (with e.g. LLM responses and tool results). Events eventually bubble up to the Runner where they are handled and the necessary side-effects are persisted in the SessionService.
Why would you want to know about events? They contain information that you might want to display in your application; e.g. you want to let your user know a tool was called to perform a certain action, any artifacts that were saved, or presenting the agent's final response.
In my resume builder, understanding events became crucial when I wanted to show users what the agent was doing (retrieving achievements, rewriting content) rather than just appearing stuck. The event system also helped me debug why certain agents terminated or why handovers weren't working as expected.
Want to dive deeper into event generation and processing? Take a look at the docs!
Runners
We have mentioned "runners" a few times in the previous section, but what are they and what do they actually do?
As Copilot put it when I asked: Runner → Agent → Flow → LLM; the runner is the entry point of your Gen AI application and orchestrates your agents, tools, and callbacks as well as takes care of interactions with any services you configured.
It takes in the user's query, starts the (root) agent and passes around resulting events. You don't have to write your own runner (unless you have very specific needs) since ADK already comes with an implementation.
Without going too deep into the details (since they're really well explained in the docs), I want to highlight one of my favourite features that comes bundled with ADK: the CLI!
You can use adk run if you want to test out your agent on the command line, or adk web if you want to do the same from the browser. Especially the latter is useful as it comes with insights into what actions your agent takes (e.g. tool calls, agent transfers, etc) as it shows you the events that flow through your system (with details!) in an interactive way:
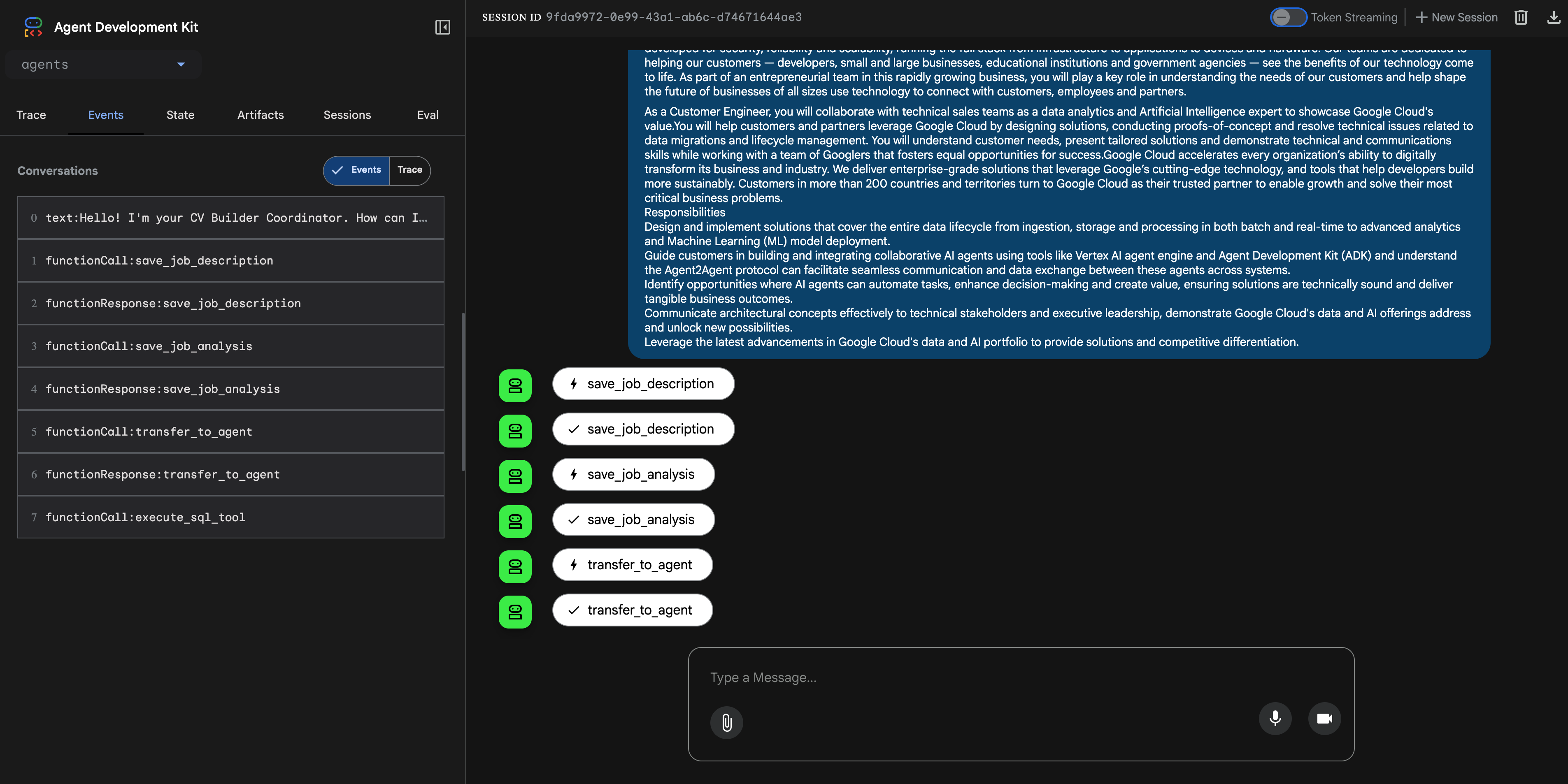
If you prefer to learn by example, I think this part of the documentation is one of the best breakdowns of the inner workings of ADK.
Workflow agents
Since we're talking about things I like about ADK, I want to highlight another one: Workflow Agents. While the concept of an agent revolves mainly around letting the agent decide what's the best course of action at each stage of the process, us, humans, in some cases might still (think we) know better...
To use the definition from the docs:
Workflow agents are specialised agents that control the execution flow of their sub‑agents
Workflow Agents operate based on predefined logic, making the execution deterministic - in these times of uncertainty, something I do like. Out of the box, there are 3 patterns:
- Sequential agents: agents executed in sequence
- Loop agent: agents executed repeatedly in sequence (until a termination condition is met)
- Parallel agents: agents executed in parallel
I experimented with the first 2 in building my demo below and it surfaces an interesting design question: let's say you want your agent to run through an "algorithm"; how much of that do you want to describe in your prompt and trust the agent to follow your instructions vs how much of that do you rather enforce through defining a Workflow Agent? More on that later.
Of course, if you're in need of other orchestration logic, ADK allows you to design an agent yourself through custom agents. But the above 3 should give you a pretty solid starting point.
State & persistence
Briefly, I wanted to touch upon state and persistence in ADK, since I am using it in my demo to communicate between the different agents.
As part of your runner definition, you can define three services for managing state:
- An artifact service for storing large (potentially non-textual) data, like a video your agent might output.
- A memory service to persist information across sessions.
- A session service which contains information about the current conversation thread. It holds the history of all events and any state you've persisted for the current conversation.
In my demo, state was useful for 2 reasons:
- Keeping track of loop-progress (as part of building the CV, I loop through past achievements of the candidate)
- Saving state for the next agent to interact with (one agent is responsible for retrieving relevant achievements, the other one is responsible for rewriting these achievements)
My state management is done through tools as described here in the docs - which makes the excellent bridge to the next section: tools!
Rich tool ecosystem 🛠️
Talking about retrieving information in an LLM setting might make you think of RAG and while you're not wrong, it's not the pattern I used in this demo. So what's a tool? Well, if "arms and legs" in the analogy doesn't work for you, here is the ADK definition:
a specific capability provided to an AI agent, enabling it to perform actions and interact with the world beyond its core text generation and reasoning abilities
Before diving into what I used, a quick look at what ADK offers tool-wise: there are built-in tools like Google Search and Code Execution, third-party tools from Google Cloud, LangChain and CrewAI that you can integrate, and, of course, your self-defined tools.
While I used self-defined tools to manage state in my project, the tooling I want to talk about is Model Context Protocol, which is, unless you haven't opened LinkedIn in 2025, probably not a foreign term for you.
Model Context Protocol (MCP)
To quote my own blogpost, there has been an increased interest in building “compound” AI systems in which we integrate an LLM as a part of a larger, composable, and modular AI system, next to the previous trend of training bigger models with more data. I listed a few potential reasons for this shift:
-
Composability: We want to go beyond text generation and automate what are currently manual workflows. For example, you don’t want to copy your manager's reply into ChatGPT; you want the LLM to be integrated into your email client. Or, as a database admin, you don’t want to type up the whole schema and relationships between all the tables in your relational database; you want your LLM to be able to pull that information as needed.
-
Grounding: an LLM (as described here by Andrej Karpathy) is more or less a probabilistic, lossy compression of the whole internet (and other bodies of text part of their training), meaning it’s working with a static snapshot of the world at training time (usually referred to as the knowledge cut-off). Moreover, since it is mainly still predicting “the next best token,” it can make up things that are not grounded in reality, which, albeit funny, are not necessarily desirable (and usually referred to as hallucinations). One way to avoid this is by giving the models retrieval access to newer information they can reference in their answers.
-
Agentic behaviour: In less deterministic scenarios, we might even want to relinquish some control over what to do and how to do a certain task. We want it to be able to choose the tools it needs, retrieve necessary information, make its own decisions , and adapt along the way.
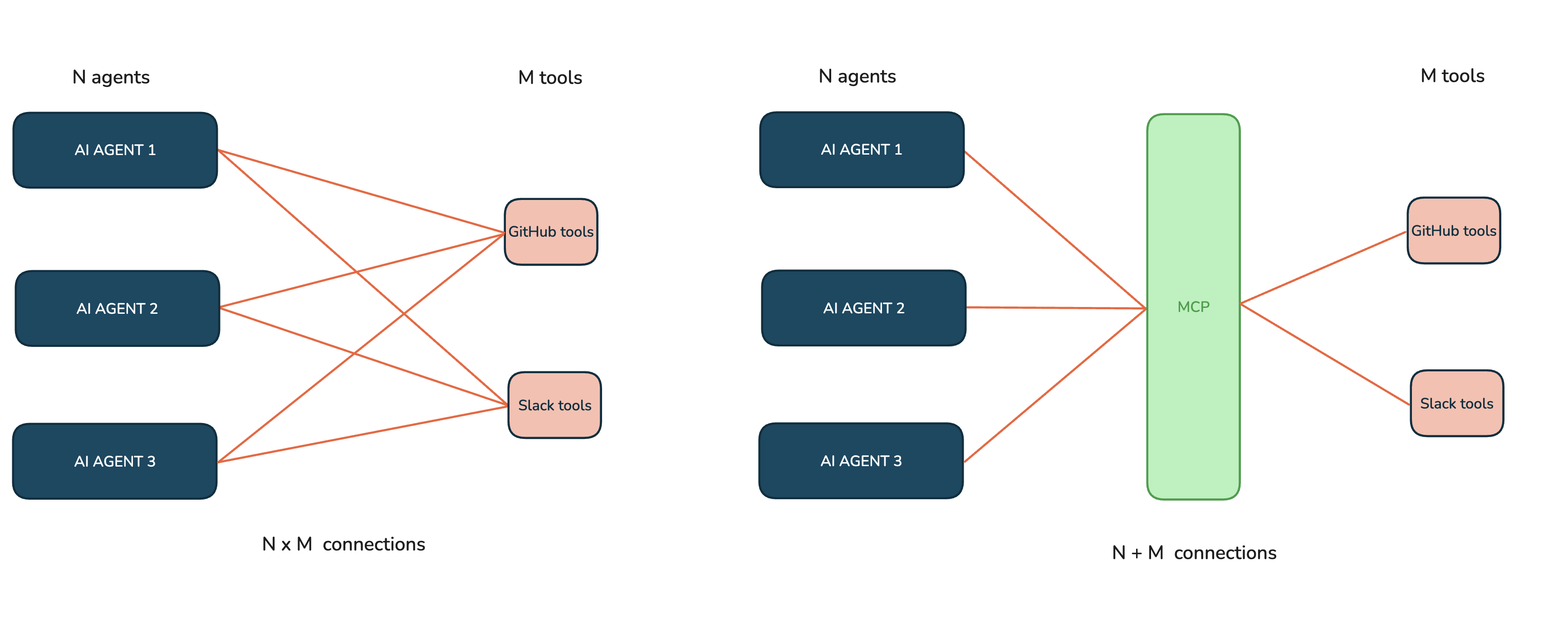
The common thread across these shifts is the communication with external systems, which, without a common standard, would require a custom implementation for each new system, leading to a fragmented landscape. By introducing Model Context Protocol at the end of 2024, Anthropic aimed to turn this N × M integration problem into an N + M integration problem by creating an open standard for two-way connections between data sources (N tools) and AI-powered tools (M clients). It’s comparable to how HTTP standardised communication between web browsers and servers.
ADK provides a strong integration with MCP so that your agent can use MCP tools OR expose ADK tools via an MCP server; discussed in the docs here and here - and we'll see how we made use of that below.
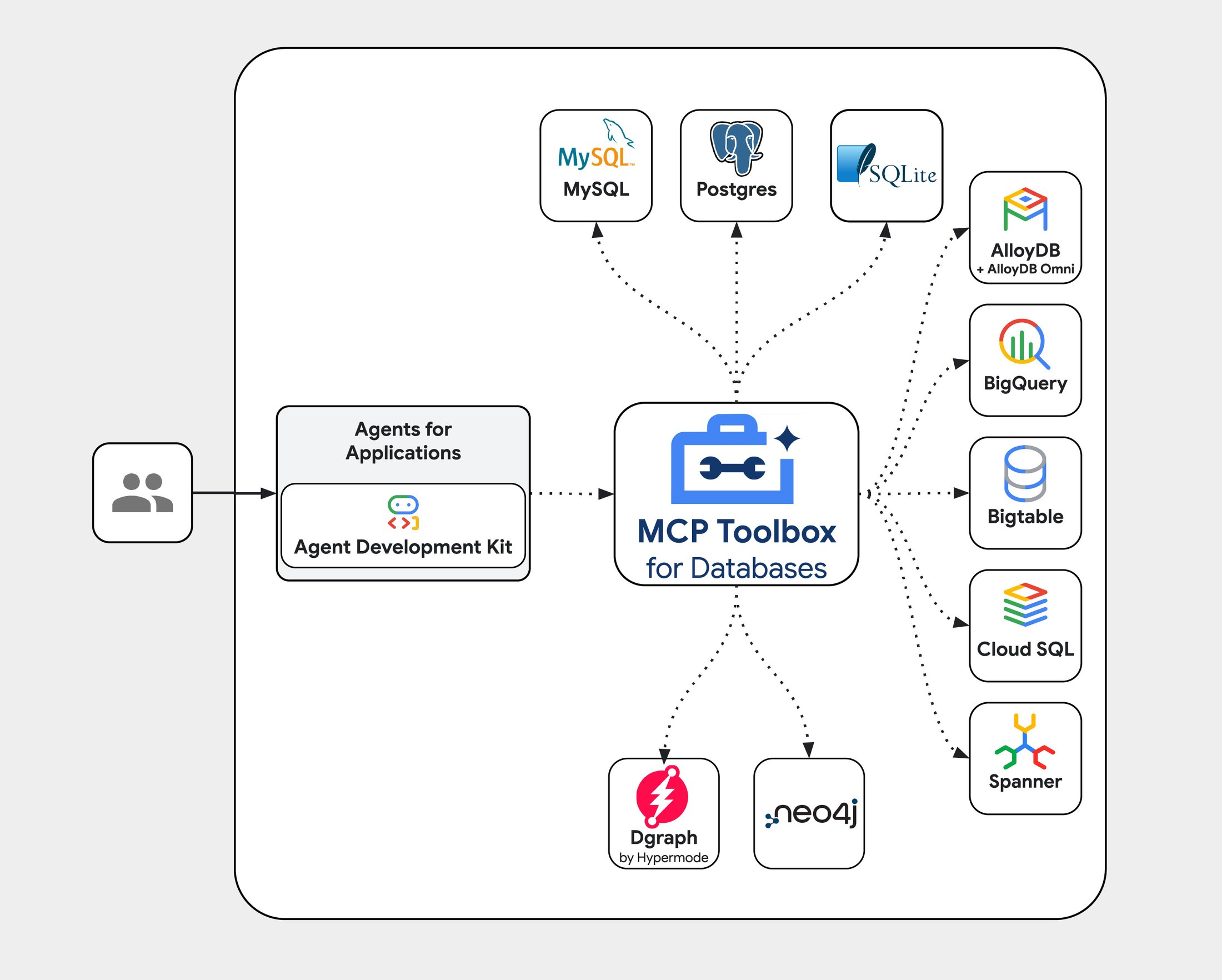
MCP Toolbox for Databases
What I want to zoom in on though is the MCP Toolbox for Databases, a separate repo that Google open-sourced at Google Cloud Next 2025.
It makes it super easy to integrate a long list of databases into your application and uses best practices out of the box. You define your source (one of the dozens currently supported), and a tool or group of tools (toolset) that you can execute against that source in a simple yaml.
In my demo, I used the toolbox to talk to a PostgreSQL database containing information about the candidate for whom we are producing a CV. Let's say I need another type of database (or want to switch out PostgreSQL for something else), this becomes a lot easier using the toolbox.
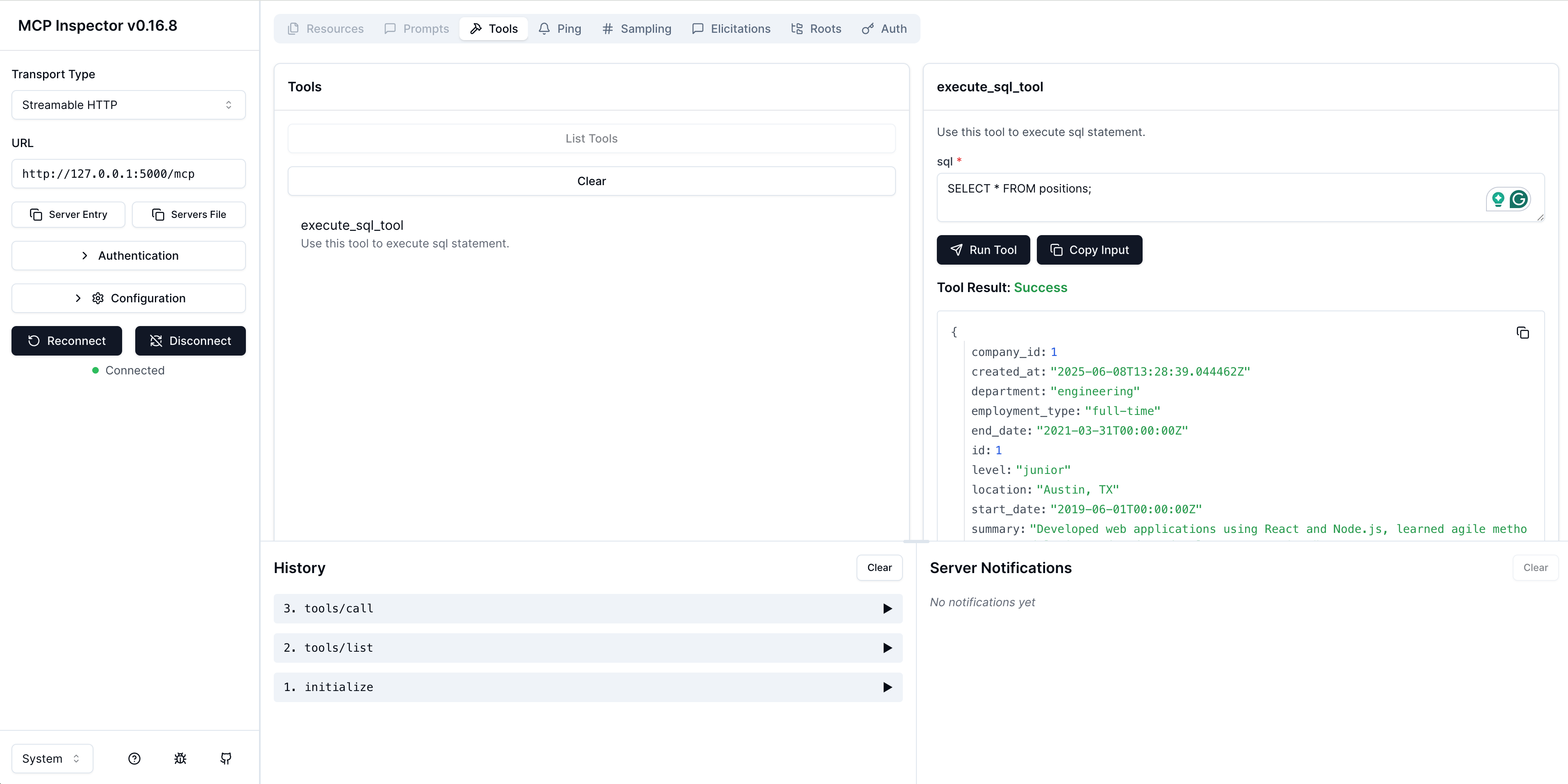
MCP Inspector 🕵🏼
One of my favourite tips at a recent hackathon is to use MCP Inspector when you're building agents with MCP. It allows you to "take the role of your agent" and see how it will be able to interact with the tools you give it, helping you to debug and guide prompts you write for your agent as well as figure out connections and capabilities. It gives you a GUI to explore and test the MCP server, list all the tools, invoke them, ... much like you would do with a normal API and Postman.
Reasoning models and Gemini
I briefly covered the newest Gemini models in my previous blog post; while I haven't read the full Gemini 2.5 technical report, I found an engaging blog post about a DeepMind agent that plays Pokémon — it highlights interesting points, including "context poisoning", which I'll discuss later in this post as part of context engineering.
What I did have time for, was to watch Andrej Karpathy's brilliant 3.5‑hour‑long video on how LLMs are "created", in which he covers the 3 different parts of model training in depth, but at the same time using human language. A refreshing (and even relaxing?) watch and probably the best 3.5 hours I spent this year. While I won't summarise the whole video here (something I might keep for a future post), at a high level, to create the state‑of‑the‑art reasoning or thinking models, these teams go through the following 3 steps:
- Pre-training: Andrej compares pre-training with reading all the textbooks available; in this step, the model acquires knowledge through the statistical patterns from a vast, internet-size (unlabeled) dataset and stores this "learning" into its parameters.
- In the next step, the first step of post-training, the model is turned from a next-token predictor into a useful AI assistant that can follow instructions. This is mainly done through supervised fine-tuning or SFT in which the model is further trained on a smaller, high-quality, curated dataset of labeled examples of prompt-response pairs. For the non-thinking models (GPT4o, Gemini 1.5, ...), this is where the process stops.
- Where the real reasoning is learned is the reinforcement learning step of the post-training. Instead of just imitating human answers from the labeled dataset, the model is given a set of problems, tries to come up with a solution and gets rewarded for a correct solution. It produces its own Chains of Thought, and observes and learns which are successful, leading to the emergence of thinking or reasoning models.
Why should we care about reasoning models in the context of agents? Thinking models are better at coming up with a plan to tackle a complex problem as they produce some reasoning and plans instead of just mimicking a "pre-programmed" answer. It will come up with a plan, the tools it needs to achieve its goal, and can, through observation of the result of its actions, come up with changes to that plan. It is, thus, an essential component, as we push our agents to resolve increasingly complex tasks.
Within the Gemini family, the top-of-the-line reasoning model is 2.5 Pro and it's the model I will put in charge of orchestrating my CV building. 2.5 Flash has the nice feature of being able to set a "budget" for thinking tokens, making it a good candidate where you still want some smarts, but also want to control costs. And as of this week, Gemini 2.5 Flash-Lite is also generally available - with a toggle to turn thinking on or off. It finds itself at the opposite end of 2.5 Pro on the speed & cost vs performance graph. Pick your poison!
Deployment ready
So enough about software, where does the hardware come in? As you might imagine, ADK has deployment options built-in, especially for Google Cloud as a target. GKE and Cloud Run are good options, but Agent Engine (part of Vertex AI) is probably the easiest (most managed) option. Given your agent, a deployment script pretty much consists of initialising the Vertex AI SDK and calling a .create() function. Once your agent is in the cloud ☁️ it will be well surrounded by:
- a persistent Agent Engine Sessions service and Agent Engine Memory Bank service to store your session data and long-term memory (as we discussed previously)
- infrastructure under the form of a managed and scalable runtime
- tools to help evaluate your agent in many different ways (evaluating the trajectory of your agent, its final response, precision/recall of the taken actions, ...)
- integration with what is still one of my favourite Google Cloud products: their observability platform, fully compatible with OpenTelemetry.
The journey from a single monolithic agent to multi-agent (and back?)
So, these are the ingredients I mostly needed as I embarked on my magic CV builder agent. The goal was twofold:
- Make it easy to select the achievements from a "portfolio" of experiences when applying for a specific job. Writing your CV is not a one-size-fits-all exercise anymore in 2025. Depending on the job you are applying for, it might be good to highlight a certain experience, while for other jobs it might be better to leave it out completely.
- Each job description might have certain keywords around what the hiring manager is looking for. In your descriptions of previous experiences that you might copy-paste into your CV, these wordings might be absent, while slightly rewording the experience might make you come out on top in the CV selection stage.
Well, it was actually threefold, but the last reason was unrelated to the actual solution: I wanted to get my hands dirty with ADK and test out a few of its concepts while applying them to a use case I could muster some care for.
So what did I come up with?
Spoiler alert: what started as "let's build a simple CV helper" turned into a masterclass in how complexity can spiral when you have powerful tools at your disposal. But the journey from simple to over-engineered taught me more about agent design than any tutorial could.
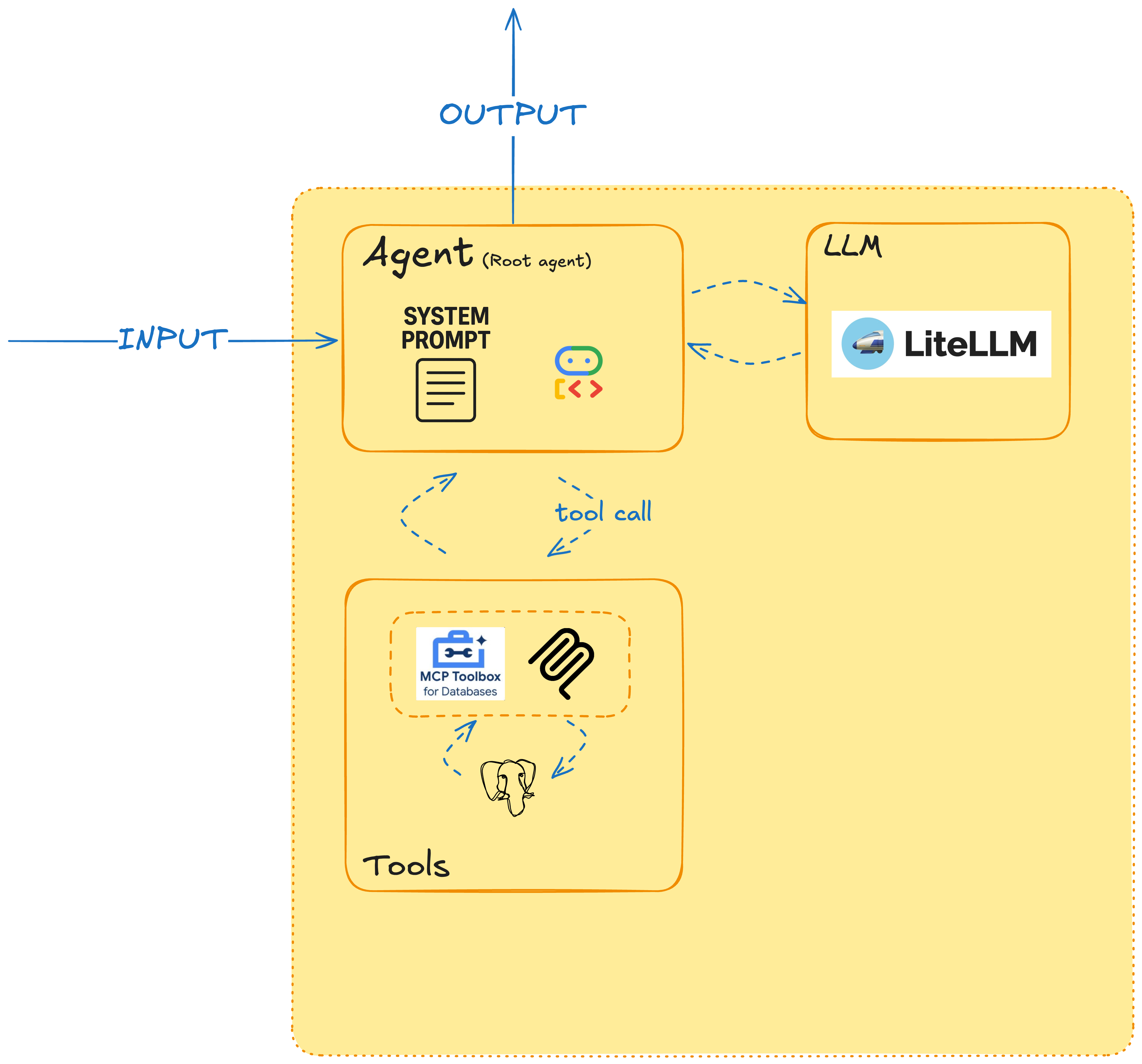
Initial architecture: keeping it simple
Deciding to keep things simple, I started with a single agent that had access to a database of past positions and experiences, each with a set of projects that had certain achievements and where certain skills were used or built.
What I liked was that it was simple to follow along with the reasoning and events flowing through the system. However, the prompt was very long, cramming in the description of each component of my "algorithm", which basically consisted of:
- Ask the user for the job description for which they want to apply
- a) Have the agent write queries and retrieve the most relevant achievements b) Present these achievements for human feedback and fine-tune until happy
- a) Start rewriting the achievements to align better with the job description b) Present these achievements for human feedback and fine-tune until happy
- Finally, output the whole CV
At this point, I wasn't even managing any explicit state, I just let everything sit in the session history... a potential recipe for disaster as we will see later. Cracks started showing as the system prompt ballooned, cramming in: user interaction guidelines, database query instructions with >10 example SQL queries, rewriting guidelines ("maintain accuracy while optimizing for keywords"), tool descriptions and parameter specifications, and error handling instructions. The context window was cluttered, and I was fighting the model rather than working with it.
Ultimately, the feeling of wanting more control over the algorithm flow, combined with an unmanageable system prompt, made multi-agent architecture seem like the obvious next step. Spoiler: it wasn't as obvious as I thought.
Going multi-agent
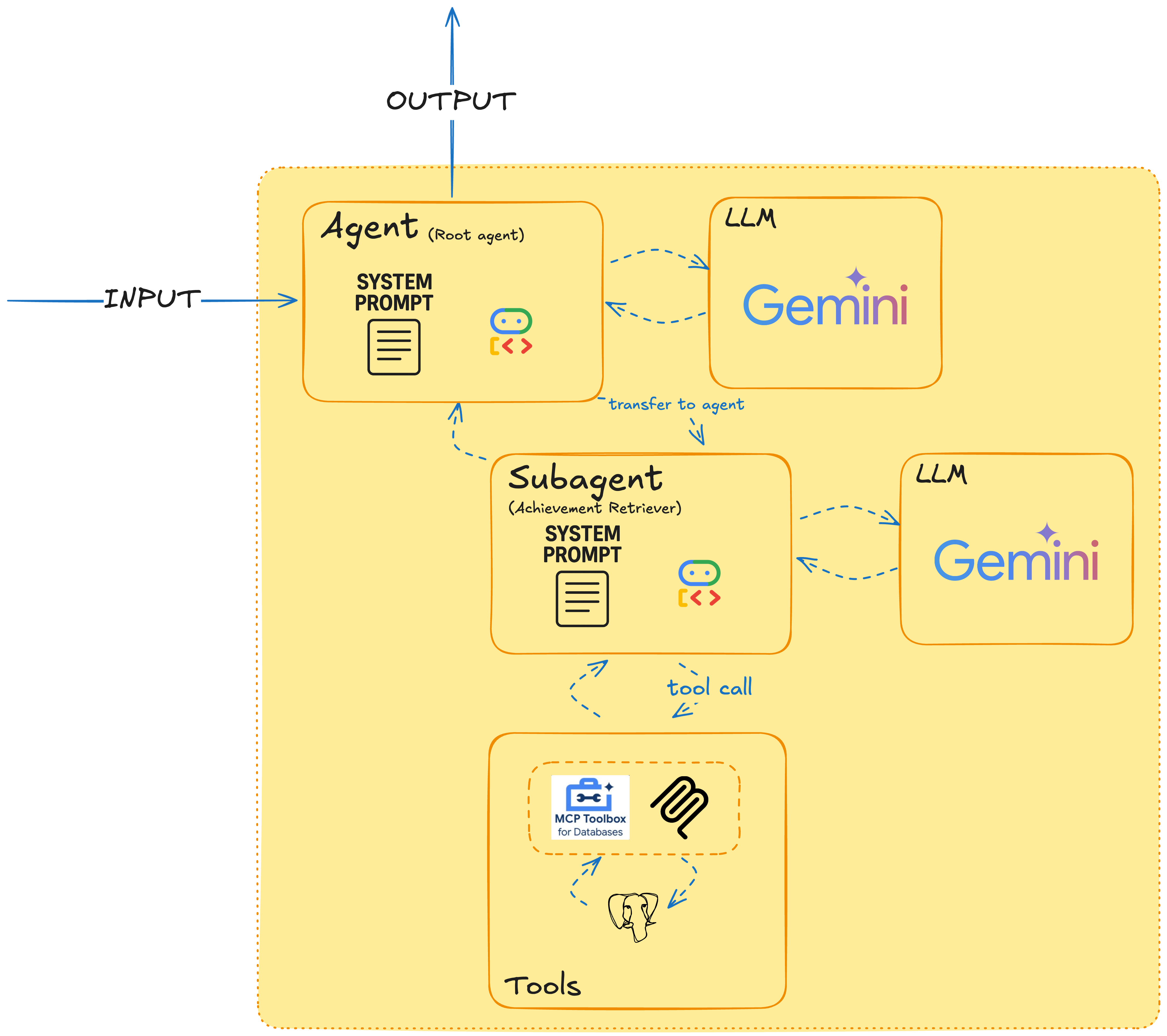
Reviewing some of the adk-samples, I found a few things I wanted to try out. Especially since I saw the loop pattern appear in my "algorithm", I was thinking towards Workflow Agents, which surely would give me more control over how my agent actually executed its work. But I resisted, and started by splitting out just 1 part of the algorithm in an agent: my retrieval agent.
Why? This was the one cluttering most of the context window with instructions around using tools and how to write the correct queries. And it felt like a good first step in defining sub agents. I was inspired by one of the documented multi-agent patterns: the human-in-the-loop pattern. My root agent would still be in charge of most of the other tasks, but my retrieval agent would come up with "achievement suggestions" that then would be passed back to the root agent where I would approve or reject.
This felt like progress! The retrieval agent was focused and performed well. The root agent's prompt was cleaner. But I noticed the root agent was still doing too many things: analysing job descriptions, managing the overall flow, rewriting achievements, and formatting the final output. The rewriting step, in particular, felt like it also deserved its own specialised focus and human-in-the-loop step.
Going MOAR multi-agent 👩👩👦👦

Now that I was at it, it was hard to stop, and those LoopAgents were really tempting. So I decided to go full-out multi-agent:
- My root agent would only be in charge of analysing the job description and, given a set of positions and (rewritten) achievements, output the final CV.
- For the middle part (preparing the set of positions and achievements), I would have a sub-agent, the "Achievement Preparation Agent" consisting of a
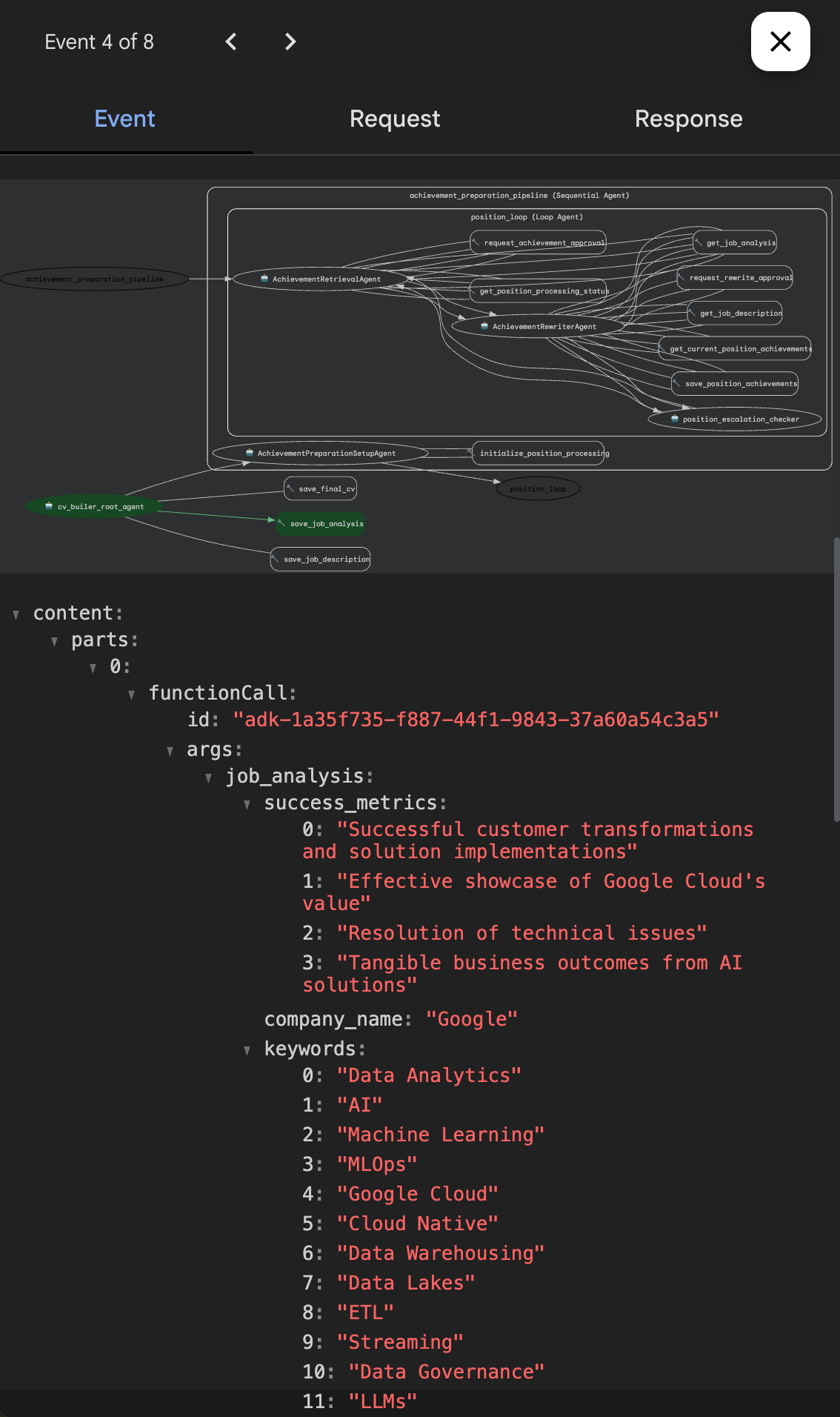
SequentialAgentwhich itself consisted of:- An Achievement Preparation Setup Agent: querying the database and initialising state for correct loop termination
- A Position Loop Agent; a
LoopAgentconsisting of:- An Achievement Retrieval Agent (this one didn't change too much from the previous one)
- An Achievement Rewriter Agent: an agent reading the approved output from the previous agent and rewriting the content until approved
- A PositionEscalationChecker, in charge of ending the loop when we covered all previous positions
At this point, I was also making extensive use of state, to facilitate communication between agents, giving them access to tools to e.g. set the job analysis information, pass around approved achievements and store the final CV, as well as tools to ask for human approval. Initially I wanted to just make it "part of the conversation" as I was doing in iteration 1 and 2, but the LoopAgent and SequentialAgent will immediately hand over execution to the next agent once the produced event is "final" - the exact reason why I went to study this section of the docs.
Stop. Take a breath. Look at that architecture. 👀
Six different agents. Sequential workflows. Loop agents. State management tools. Human approval workflows. For... generating a CV.
You might be thinking "you totally over-engineered this simple task" and I wouldn't try to argue that point. The architecture had become so complex that debugging a simple issue required tracing through multiple agent handoffs, state changes, and event flows. Hence, I am pretty sure there will be a v4 architecture.
Some learnings along the way
While building and learning, I went off on a few tangents, (some of) which I am happy to share (others felt like a rabbit hole 🐇🕳️ in hindsight 😅)
Context engineering ⚙️
I wouldn't be writing a contemporary blog post (when I started writing this was still red hot) without hopping on the latest hype word (and it's somewhat relevant to what I was complaining about above regarding cramming everything into 1 system prompt).
Simon Willison's describes the (very) short history of the term in his blog, and surely enough, we see our, in the meantime good friend, Andrej Karpathy coming back as well:
+1 for "context engineering" over "prompt engineering".
— Andrej Karpathy (@karpathy) June 25, 2025
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window… https://t.co/Ne65F6vFcf
Why discuss "context engineering" when talking about agents? Well, the context-window of your LLM is your only way to steer the behaviour of your agent and it's a finite resource. As we move away from single prompt Q&A where we are in control of what to put in and towards relinquishing a lot of control of what happens in that context window to LLMs, tools, other agents etc., we might want to become more conscious of crafting a system to do so well. Putting in the wrong information might trip up your LLM over making the correct reasoning or tool call. Phil Schmid goes even as far as saying "most agent failures are not model failures anymore, they are context failures".
I do like the concept of "context engineering" since it puts the engineering and determinism back into building things with LLMs which are uncertain by definition (just as the BAIR blogpost did when talking about compound AI systems, or DSPy did when looking into automating prompt optimisation). Let's take a look at how Phil Schmid defines it:
Context Engineering is the discipline of designing and building dynamic systems that provides the right information and tools, in the right format, at the right time, to give a LLM everything it needs to accomplish a task.
For most people, this would be "the messages they send to their ChatGPT". But when building behind the scenes, we know it's a lot more than that: your system prompt, any retrieved information when using RAG, all the previous messages in the conversation, and, last but not least, the tools with their descriptions and interface.
Originally, when long(er) context windows were launched (with Gemini 1.5 leading the way), the problem was centered around hiding and finding a certain fact (needle) in that context window filled with irrelevant information (the haystack). While the results there were very promising (e.g. "Gemini 1.5 Pro achieves near-perfect “needle” recall (>99.7%) up to 1M tokens of “haystack” in all modalities").
Recent research shows though that when combining long context with reasoning, even state-of-the-art LLMs are struggling:
Our results suggest that current LLMs have significant room for improvement in practical long-context applications, as they struggle with the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks.
Other research shows that LLMs can suffer from Context Distraction:
[...] many models show reduced performance at long context as evidenced by failing to follow instructions or producing repetitious outputs.
We can see similar research pop-up for finding the right tool & tool related information in a long context window with a lot of distracting information: ToolHaystack is a benchmark that tests tool use capabilities (in which the needle is "task-relevant context essential to reach the target goal" and the "haystack" consists of distracting information) and shows that even the strongest current models collapse under realistic long-term scenarios.
That same challenge re-emerges in tool use: as you pack more tools (and thus more context) into the prompt, the model must pick one from a growing list, and its accuracy drops. “Benchmarking Tool Retrieval for Large Language Models” shows that performance degrades sharply when the tool library grows large, making the right tool harder to surface. As Drew Breunig calls out on his blog: every model tested performs worse once more than one tool is available.
Of course, there will be solutions to this problem. Early work in the space includes: in “Gorilla: Large Language Model Connected with Massive APIs” only relevant API documentation is retrieved at runtime, reducing hallucinations and improving tool selection under changing environments. In “Less is More: Optimizing Function Calling for LLM Execution on Edge Devices” the number of tools exposed to the model is selectively reduced, resulting in improved execution speed and energy efficiency. “RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation” pre-filters the candidate tool set before passing it into the LLM, recovering much of the accuracy lost to prompt bloat.
While I think a deeper rabbit hole is justified for this topic and how agentic frameworks like ADK help you manage context better, that will make me procrastinate the release of this post even more... So I'll leave it at:
- Own your context window
- It is seemingly a WIP for ADK at the moment - the master issue is open since early June
- Research into Active Context Memory systems seems to be underway
Agent vs Tool vs AgentTool
By now, we know what tools and agents are - but you might have come across something called AgentTool in the ADK docs. At some point in your agent design, the question of having multiple agents in your architecture might pop up and with that, the question on how they will communicate. I adopted shared state in my demo, but there are two other patterns possible: Agent Transfer and AgentTool.
In Agent Transfer, your agent will relinquish control to the agent it transfers to and let them run the rest of the interaction. This can be useful if for example it needs to collect additional information or input from the user to achieve the goal (think of a specialist). Meanwhile, Agent Tools is a lot closer to a normal tool call - the agent gets called with some input and returns a result - much more transactional, but delegating part of its responsibility to another agent.
Like Bo Yang (ADK tech lead) pointed out in his blog a nice way to think about it is if the support agent connects you with a different agent, or just quickly consults them internally.
Further reading in the docs: here and here
To multi-agent, or not to multi-agent, that's the question
Funnily enough, around the time I started putting together this blog post, two articles related to multi-agent systems came out of two leading AI labs in the span of two days:
- On 12 June 2025 Cognition released "Don’t Build Multi-Agents"
- On 13 June 2025 Anthropic released "How we built our multi-agent research system"
so I knew we were off to a good start. What I took away was that it's better to start simple, and if you're planning to multi-agent that you should accept more risk for things to go awry; and thus invest in carefully curating context (hello, context engineering 👋), as well as traceability and debuggability. Even Anthropic was struggling with this, so if you can't debug it, you probably shouldn't deploy it. Cost is also worth thinking about: a 15x mark-up for multi-agent vs normal chat is more than an order of magnitude, so it's worth thinking about justifying that first. 💸 A few things I will definitely carry with me when working on my v4 architecture and a decent way to end this blogpost.
Conclusion
What began as a weekend project became a journey through the full spectrum of system complexity. This arc taught me more about ADK and multi-agent design than staying within reasonable bounds ever could have. Beyond its clear docs and solid abstractions, ADK’s workflow agents hit a sweet spot between autonomy and determinism—useful when you need predictable systems. The bigger lesson, as Richard Seroter aptly put it, "code was the least interesting part" of building a multi-agent application. Instead, we need to split responsibilities deliberately, curate context ruthlessly, and justify every layer of complexity.
While the multi-agent approach gave me fine-grained control and clear separation of concerns, it also introduced significant complexity that may not have been warranted for the task at hand. The 15x token overhead that Anthropic reported for their multi-agent systems suddenly feels very real when you see the system in action.
It very much feels like "I over-engineered a CV bot so you don't have to", but sometimes that's exactly what you need to do to learn where the boundaries should be.
This exploration has opened up several interesting directions for future development. On the technical side, I'd like to leverage ADK's artifact service for persisting CV outputs and experiment with Imagen through MCP servers for automating design, while digging deeper into the full Agent Engine deployment. More importantly though, I'm keen to simplify the architecture, diving deeper into context engineering techniques, and better understanding when workflow orchestration actually adds value versus unnecessary complexity. I guess I'll see you in the next few months!